生产者学习
1.1 生产者消息发送流程
在消息发送的过程中,涉及到了两个线程——main线程和Sender线程。在main线程中创建了一个双端队列RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka Broker。
生产者如何发送的?
现在Main线程中将数据进行处理,处理成IO型数据,然后调用sender进行发送
Main:
1.读取生产者配置
2.产生数据
3.过滤数据(校验什么的)
4.序列化
5.放入缓冲区 RecordAccumulator
6.发送Sender
细节: 考虑的问题 1.生产者配置的读取和修改 2.数据的过滤与分区, 3.缓冲区是如何设置的,大小
4.发送(发送失败怎么样,请求区的大小)
这里注意一下,可以在缓冲区对数据进行压缩,这样就提高缓冲区的容量和发送的数据量,提高吞吐量
1.2 同步发送与异步发送
1.什么是同步和异步
同步就是,串行,一条龙 异步 一起运行
举例: 餐馆点餐
同步: 需要等服务员过来,让服务员记录,
异步: 点餐APP直接点餐,交给队列,让他自己运行
2.发送的同步异步
同步:需要得到返回值
异步:发送过去不管了
3. 分区好处
啥是分区?
将一个数据块分成多个数据块
将数据分布式处理了
存储: 可以分在多个机器上, 也可以整多个副本。便于存储,同时提高健壮性
IO:多个数据块可以同时进行发送接收消费。生产者可以以分区为单位发送数据,消费者可以以分区为单位进行消费
4. 默认分区器
前提条件: 1.分区 2.key值
规则:
- 1存在,按1分区
- 1不存在,按2.key值对分区数取余得到的值分区
- 1.2都不存在 随机选个分区,等这个批次发送完了,再换
3 就是粘性分区
那么粘性分区的缺点是什么?
因为缓冲区溢出的条件是,大小和时间双重判断,如果大小不够,但是时间够了,还是会发走,这样,最后导致,分区上产生数据倾斜
如何解决的?
3.3.1 Kafka去掉粘性分区的时间控制,批次只由大小判断
1.3.自定义分区器
1.思路
- 1.实现接口Parititoner,重写相关方法
- 2.修改配置 将partitioner设置为默认配置
2.1 自定义分区器代码
public class MyPartitioner implements Partitioner {// 自定义分区器 实现partitioner接口// 1.分区方法@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 获取消息String data = value.toString();// 创建partition 作为最后的分区标识int partitions;// 分区逻辑// 根据含有的字符串进行判断 判断进入哪个分区if (data.contains("atguigu")){partitions = 0;} else if (data.contains("shangguigu")){partitions = 1;} else {partitions = 2;}return partitions;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
2.2 主类
package com.atguigu.producer;import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;
import java.util.concurrent.ExecutionException;
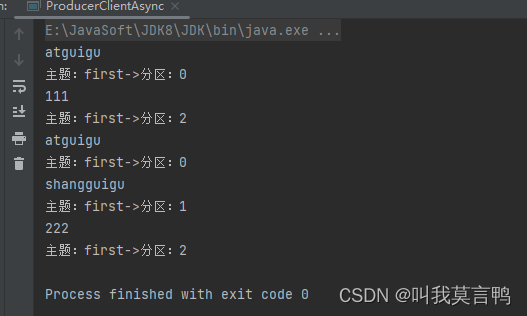
import java.util.concurrent.Future;public class ProducerClientAsync {public static void main(String[] args) {// 0 配置对象Properties properties = new Properties();// --指定kafka的Broker地址properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");// -- 1.指定序列化器 序列化器的全限定类名properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());//.setProperty(ProducerConfig.LINGER_MS_CONFIG,"0");// -- 2.设置分区器properties.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG,MyPartitioner.class.getName());// -- 3.获取客户端连接对象KafkaProducer<String,String> kafkaProducer= new KafkaProducer<String,String>(properties);// key是主题 v是发送内容 这里注意一下// -- 4.发送数据String[] str= {"atguigu","111","atguigu","shangguigu","222"};for (int i =0; i < str.length; i++) {System.out.println(str[i]);try {kafkaProducer.send(new ProducerRecord<>("first", str[i]), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception == null){System.out.println("主题:" + metadata.topic() + "->" + "分区:" + metadata.partition());}else {// 出现异常打印exception.printStackTrace();}}}).get();} catch (InterruptedException e) {throw new RuntimeException(e);} catch (ExecutionException e) {throw new RuntimeException(e);}}kafkaProducer.close();}
}
3.面试细节
1.如何提高生产者的吞吐量
- 批次大小调到16
- 将等待时间改成50-100ms 默认是0
- 压缩数据量,这样每次发送的数据就多了
- 加大缓冲区大小,进来的数据变多,发送也能提上去
2.生产者如何保证数据可靠性的
主要通过ack机制
1.什么是ACK机制?
根据ack值来决定Kafka集群服务端的存储应答
- ack=0 最低 生产者只管发送,不用接收
- ack=1 中等 生产者发送完需要等待Leader保存后回应,
- ack=-1 最高 生产者发送完需要等待所有副本保存后回应
2.分析ACK机制
性能与安全是成反比的
所以,-1虽然最安全,但是效率最低
3.如果将ACK调到-1会出现什么问题?
有可能出现数据重复发送与接收
比如,在同步的瞬间,Leader死掉,但是其他副本已经落盘,这时候,就是问题了。
因为Leader死掉了,所以会直接更换Leader,选出一个副本作为Leader,注意,这时显示没有收到内容,所以,send重新发送,这时候,每个副本上,收到的就是2份该数据了。
4.应用场景
acks=0 几乎不用
acks=1 传输普通日志,允许丢失
acks=-1 传输高可靠性数据,一般与钱有关
5.ACK=-1一定可靠么?
不一定
如果分区副本数设置为1 ,或者ISR里应答的最小副本数设置为1(默认也是1),这时候,ack=1效果相同了。
也就是说,应答一个,就能走,就没意义了
所以需要完全可靠就需要配置一下
ACK=-1 & 分区副本大于等于2 & ISR应答最小副本数量大于等于2
3. 数据去重
1.概念
至少一次:一次或者多次 完全可靠
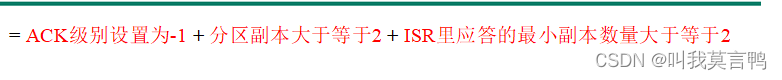
最多一次:直接不管回复只管发送 ack=0
至少:保证数据不丢失,但是无法保证数据不重复
最多: 无法保证数据不丢失
1.如何解决数据的重复发送与接收的问题,同时保证数据的不丢失
注意,这里解决的是sender和服务端的重复发送与接收,而不是生产者本身发送多个重复消息的问题,这个要搞清楚。
一般重复问题,都是通过标识来判别,从而去重的
Kafka 0.11 引入 幂等性和事务
精确一次: 幂等性 +至少一次(ack=-1 & 分区副本>=2 & ISR最小副本>=2)
4.幂等性
1.概念
啥是幂等性,标识一个消息的唯一标识
<pid,partition,Seqnumber>
Pid 是会话ID,每次重新生成会话,就会重新生成PID
partition是分区 标识 消息是哪个分区的
Seqnumber是单调递增的标识,注意,这是每个分区独享的
这三个在一起,才是唯一标识。
2.如何使用幂等性
开启参数enable.idempotence 默认为true,false关闭。
开启开关就行


![[PyTorch][chapter 49][创建自己的数据集 1]](https://img-blog.csdnimg.cn/9044691cce7d44f989c4672fec3b273d.png)

![[PyTorch][chapter 50][创建自己的数据集 2]](https://img-blog.csdnimg.cn/b28ab32903b142b8ac5f78fb0ea35d87.png)

![[足式机器人]Part3机构运动微分几何学分析与综合Ch03-1 空间约束曲线与约束曲面微分几何学——【读书笔记】](https://img-blog.csdnimg.cn/303488597c624fe0b2cb55cbc3532adc.png)