文章目录
- 常见限流算法学习
- 前言
- 限流算法基本介绍
- 固定窗口计数器限流算法
- 计数器限流算法相关介绍
- 计数器限流算法的实现(基于共享变量)
- 计数器限流算法的实现(基于Redis)
- 滑动窗口计数器算法
- 滑动时间窗口算法相关介绍介绍
- 滑动时间窗口算法实现
- 漏桶限流算法
- 漏桶限流算法相关介绍
- 漏桶限流算法实现
- 令牌桶限流算法
- 令牌桶限流算法相关介绍
- 令牌桶限流算法实现
- Sentinel实现限流
- Guava实现限流
- 总结
- Bug记录
常见限流算法学习
前言
本文主要讲解常见的几大限流算法,包括:固定窗口计数器限流算法、滑动窗口计数器限流算法、漏桶限流算法、令牌桶限流算法,此外还会讲解如何使用Sentinel、谷歌提供的Guava工具包中的RateLimiter限流工具类实现限流,如果你觉得本文对你有所帮助,欢迎点赞,您的鼓励将是我持续输出的动力
PS:如果文中有描述不当、错误、侵权的地方还恳请您能告知博主,博主将立即做出修改,同时将送上我真挚的感谢🌹
限流算法基本介绍
-
什么是限流?
限流(Current limiting)是一种控制系统中请求或流量的速率的机制。在计算机系统或网络应用中,通过限制单位时间内的请求数量或数据传输速率,可以有效地平衡系统负载,保护后端资源免受过多的请求或流量冲击。
Web开发中的例子:比如我吗有时候在访问一个网站时,如果我吗刷新太快就会得到一个失败的结果,比如这个接口
https://api.nbhao.org/v1/email/verify用于判断邮箱是否真实存在,这个接口一秒钟只会处理一次请求,其它请求直接回返回"Frequent requests"的错误信息生活中的例子:我们去看演唱会、景区旅游,这些地方只会卖固定数量的票,目的就算限制人流量过大,造成严重的交通堵塞
-
限流的作用有哪些?
- 保护后端资源:通过限制请求或流量的速率,可以避免过多的请求冲击后端服务器或资源,防止系统负载过高、资源耗尽,从而保护后端资源的稳定性和可靠性。
- 防止恶意行为:限流可以防止恶意攻击或滥用系统资源的行为。例如,防止暴力破解密码、DDoS 攻击、爬虫等对系统造成的不良影响。
- 提高系统性能:通过限制并发请求数量或数据传输速率,可以有效平衡系统负载,避免系统因过度请求而导致性能下降,从而提高系统的响应速度和吞吐量。
- 保证服务质量:限流可以确保系统以合理的方式为用户提供服务,避免由于突发流量导致的系统崩溃或服务不可用的情况,从而提供更好的用户体验。
- 控制成本:通过限制并发请求或流量,可以控制系统的资源消耗和成本。避免过多的请求占用过多的服务器资源,并在需要时调整限流策略来适应实际需求。
-
常见的限流策略有哪些?
- 固定窗口计数器(Fixed Window Counter):在固定时间窗口内计数请求的数量,当请求数超过设定的阈值时进行限流。
- 滑动窗口计数器(Sliding Window Counter):与固定窗口计数器类似,但是它采用滑动窗口的方式来计数,可以更加细粒度地控制请求的流量。
- 令牌桶算法(Token Bucket Algorithm):通过使用令牌桶来限制请求的处理能力,每个请求需要从令牌桶中获取令牌才能执行,令牌桶以一定速率生成令牌。
- 漏桶算法(Leaky Bucket Algorithm):模拟一个漏桶,以固定的速率接收请求并排出,超出桶容量的请求将被丢弃或者等待下一个时间窗口再处理。
这里在限流前,先对http://localhost:10086/hello接口进行一个压测

可以看到 并发量为 493,结果系统都能够成功接收,也就是当前接口是处于来者不拒的状况(这有点危险啊,如果这样的接口上线,遇到不怀好意的人,同时如果服务器是直接查询数据库的话,那么服务器会被打爆!)
固定窗口计数器限流算法
计数器限流算法相关介绍
计数器限流算法(Counter current limiting algorithm)是一种简单直观的限流算法,它是采用固定窗口计算策略实现的,它基于一个计数器来统计单位时间内的请求数量,并与预设的阈值进行比较。如果请求数量超过了阈值,则拒绝额外的请求;否则,接受请求并将计数器递增。

-
计数器限流算法的优缺点
- 优点:实现简单且直观,可维护性低,同时具有较低的延迟和较高的吞吐量
- 缺点:
- 突发流量问题:计数器限流算法无法应对突发流量的问题。当系统在一个时间窗口内接收到大量请求时,可能会导致计数器迅速增加并超过阈值,从而拒绝后续的请求,即使这些请求是合理的。
- 不平滑:计数器限流算法可能导致请求的不平滑处理。因为计数器仅基于单位时间内的请求数量进行判断,如果请求数量出现波动或分布不均匀,可能会导致某些时间窗口的请求被拒绝,而另一些时间窗口的请求被接受,从而影响请求的公平性。
- 无法适应业务需求:计数器限流算法缺乏灵活性,难以根据具体业务需求进行调整。例如,对于不同类型的请求或不同优先级的用户,可能需要采取不同的限流策略,而计数器限流算法很难满足这种个性化的需求。
- 时间窗口的选择:选择合适的时间窗口长度是计数器限流算法的关键,但这并不是一个通用的标准,需要根据具体应用场景进行调整。时间窗口过短可能会导致频繁的计数器重置和请求拒绝,而时间窗口过长则可能无法及时响应流量波动。
- 不精确的计数:在高并发或分布式环境中,多个请求同时更新计数器可能引发竞争条件,导致计数不准确。解决这个问题可能需要引入同步机制或使用分布式锁等措施,增加了复杂性和性能开销。
-
计算器限流算法的适用场景:
- 简单的请求频率控制:当需要限制某个接口或服务的请求频率时,可以使用计数器限流算法。例如,每秒钟最多允许处理多少个HTTP请求。
- 基本的并发连接控制:当需要限制系统中的并发连接数量时,可以使用计数器限流算法。例如,在数据库连接池中,控制同时打开的连接数量。
- 资源访问控制:当某些资源需要限制访问次数或频率时,可以使用计数器限流算法。例如,API密钥每分钟最多允许发起多少个请求。
- 防止简单的恶意攻击:当需要防止恶意攻击或滥用系统的行为时,计数器限流算法可以提供一定程度的保护。例如,防止暴力破解密码或爆破登录接口。
- 低延迟要求的场景:由于计数器限流算法的简单性,它通常具有较低的延迟和较高的吞吐量,因此适用于对实时性要求较高的场景。
温馨提示:如果想要更加灵活和精确的流量控制,不推荐适用这种限流算法
-
计数器限流算法的常见实现
- 基于共享变量实现:利用一个共享变量来记录窗口中已访问请求的数量
- 优点:
- 可以使用Redis提供的数据结构(如计数器、有序集合等)来方便地实现限流算法。
- 分布式环境中可以共享和同步状态,适用于多个节点或进程间的限流控制。
- Redis具备高性能、高可用性和持久化等特性,适合处理大规模并发请求和重启后的状态恢复。
- 缺点:
- 需要额外的网络开销,每次限流判断都需要与Redis服务器进行通信。
- 对于简单的限流场景,引入Redis可能会增加系统的复杂性和部署成本。
- 对于极高频率的限流操作,Redis服务器的性能可能成为瓶颈。
- 优点:
- 基于redis实现:利用redis来记录窗口中已访问请求的数量
- 优点:
- 无需引入额外的组件或网络通信,限流判断直接在应用内部进行。
- 简单直观,适用于简单的限流策略和低并发场景。
- 在单机环境下,性能较好,无网络延迟。
- 缺点:
- 在分布式环境中,共享变量的同步可能会引发竞争条件和一致性问题。
- 难以在多个节点或进程间共享状态,不适用于分布式系统的限流控制。
- 可能需要额外的线程同步机制来保证并发访问的安全性。
- 优点:
如果系统很简单,且没有分布式需求1,推荐使用方式一;如果系统有分布式需求的,推荐使用方式二
- 基于共享变量实现:利用一个共享变量来记录窗口中已访问请求的数量
计数器限流算法的实现(基于共享变量)

具体实现逻辑如下:
- 初始化一个计数器变量
counter,用于记录单位时间内的请求数量。 - 设置一个固定的时间窗口长度,例如1秒钟。
- 每当有请求进来时,将计数器递增。
- 判断当前时间是否超过了时间窗口的结束时刻:
- 如果超过了时间窗口的结束时刻,说明进入了新的时间窗口。
- 重置计数器为1。
- 更新时间窗口的结束时刻。
- 接受当前请求。
- 如果没有超过时间窗口的结束时刻,继续判断计数器的值是否超过了预设的阈值。
- 如果超过了阈值,拒绝当前请求。
- 如果未超过阈值,接受当前请求。
- 如果超过了时间窗口的结束时刻,说明进入了新的时间窗口。
package com.ghp.demo.limiter.impl;import com.ghp.demo.limiter.TrafficLimiter;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;import javax.annotation.Resource;/*** @author ghp* @title* @description 基于共享变量实现计数器限流器*/
@Component(value = "CounterLimiterSharedVariable")
public class CounterLimiterSharedVariable implements TrafficLimiter {// 这个变量,我用来测试的,无关紧要private static int i = 0;@Resourceprivate RedisTemplate redisTemplate;/*** 窗口起始时间*/private long start = System.currentTimeMillis();/*** 请求次数*/private int count;/*** 每秒限流的最大请求数,一个时间窗口内超过这个阈值就会被限流*/private int threshold = 1;/*** 时间窗口时长,单位ms。* 结合 threshold 参数,这两个属性共同决定接口并发访问量* 此时 threshold 是1,而 interval 是 1s,这就意味着一秒钟接口只能被访问一次*/private long interval = 1000L;/*** 判断是否限流** @return返回 true代表限流,false代表通过*/@Overridepublic synchronized boolean limit() {long now = System.currentTimeMillis();System.out.printf("第%s个请求,当前时间%s时窗口中请求数量为%s,\n", i++, now, count);// 判断当前请求是否在当前时间窗口if (now < start + interval) {// 在当前时间窗口内,判断当前时间窗口请求数加1是否超过每秒限流的最大请求数if (count + 1 > threshold) {return true;}// 当前时间戳口内的请求数量并未超过阈值count++;return false;} else {// 不在当前时间窗口内,直接开启新窗口,并且重置请求次数start = now;count = 1;return false;}}}

qps为10时,成功请求数为10,符合我的预期
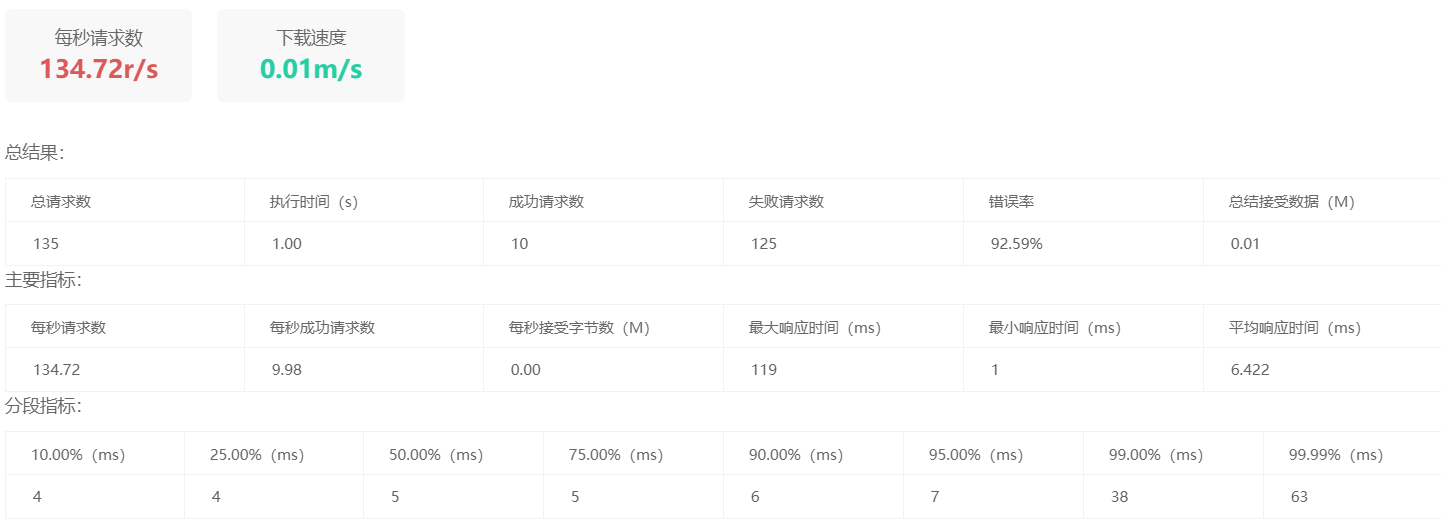
计数器限流算法的实现(基于Redis)
package com.ghp.demo.limiter.impl;import com.ghp.demo.limiter.TrafficLimiter;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;/*** @author ghp* @title* @description 基于Redis实现计数器限流器*/
@Component(value = "CounterLimiterRedis")
public class CounterLimiterRedis implements TrafficLimiter {// 这个变量,我用来测试的,无关紧要private static int i = 0;@Resourceprivate StringRedisTemplate stringRedisTemplate;/*** 一个窗口中能够接收的最大请求数量*/private int threshold = 1;/*** 时间间隔,单位ms。决定窗口的大小* 结合 threshold 参数,这两个属性共同决定接口并发访问量* 此时 threshold 是1,而 interval 是 1s,这就意味着一秒钟接口只能被访问一次*/private long interval = 3000L;/*** 判断是否限流** @return返回 true代表限流,false代表通过*/@Overridepublic synchronized boolean limit() {String key = String.valueOf(System.currentTimeMillis() / interval);Long result = stringRedisTemplate.opsForValue().increment(key);System.out.printf("第%s个请求,当前时间%s时窗口中请求数量为%s,\n", i++, key, result);stringRedisTemplate.expire(key, interval, TimeUnit.MILLISECONDS);// 当前当前时间窗口中的请求数量是否达到阈值if (result > threshold){// 达到阈值,直接限流return true;}// 未达到阈值,放行return false;}
}

滑动窗口计数器算法
滑动时间窗口算法相关介绍介绍
滑动时间窗口算法(Sliding time window algorithm)是一种在时间序列数据中进行实时计算的方法。它通过定义一个固定长度的时间窗口,在该窗口内对数据进行处理和分析。
-
滑动时间窗口算法优缺点
- 优点:
- 实时性:滑动时间窗口算法能够实时对数据进行处理和分析,适用于需要及时获取数据动态变化的场景。
- 灵活性:通过调整时间窗口的大小,可以控制对历史数据和近期数据的权重,对于不同的应用场景具有灵活性。
- 节省内存:该算法只保留固定长度的数据窗口,不需要保存全部历史数据,从而节省内存空间。
- 缺点:
- 数据丢失:由于只保留固定长度的数据窗口,超出窗口范围的数据将会被丢弃,可能导致一些信息的丢失。
- 窗口大小选择:合适的窗口大小需要根据具体应用需求来确定,选择不当可能会导致结果不准确或者无法满足需求。
- 算法复杂度:在一些情况下,滑动时间窗口算法的计算复杂度较高,特别是在处理大规模数据时,可能会对系统性能产生一定影响。
- 优点:
-
滑动时间窗口算法适用场景
- 实时统计:比如统计过去5分钟内的请求次数、平均响应时间等指标。
- 异常检测:通过比较当前时间窗口内的数据与历史数据,可以判断是否存在异常情况。
- 预测分析:使用滑动时间窗口可以获取一段时间内的数据趋势,从而进行预测和分析。
这个滑动窗口本质是多个固定窗口的集合,相当于化整为零的思想,在原本一个大窗口的基础上再划分一些小窗口(比如:之前在计数器限流算法中,一个窗口是1秒钟,而言在我我们再将这个窗口划分出10个小窗口,每个小窗口为100毫秒),每次计数都是记录当前窗口前的9个窗口,而不是之前一样直接将整个窗口给清零重新计数,这样做的好处很明显,能够让计数更加精确,避免之前计数器限流算法中出现的,两个窗口中间的流量是整个窗口流量的2倍!窗口划分的越细,那么精度就越高,同时维护成本也就越高,性能也就越低。
不可避免的,这个滑动事件窗口也存在一定的精度问题,(当然这个精度是可以由我们自己控制的),这个问题其实就算之前固定窗口存在的问题,只是现在我们将这个问题给细化了,但是仍然存在!
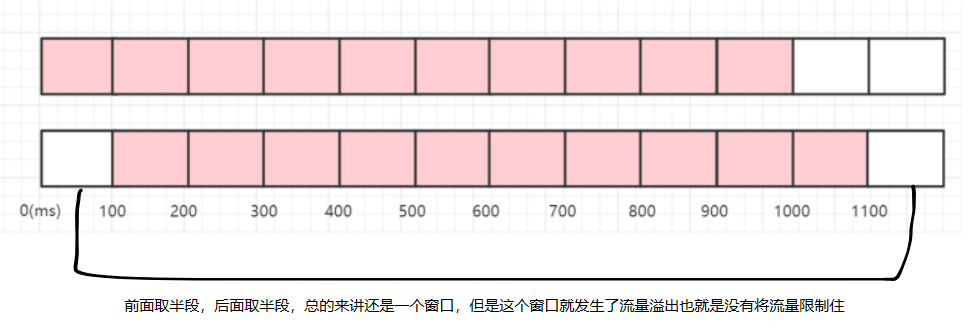
滑动时间窗口算法实现
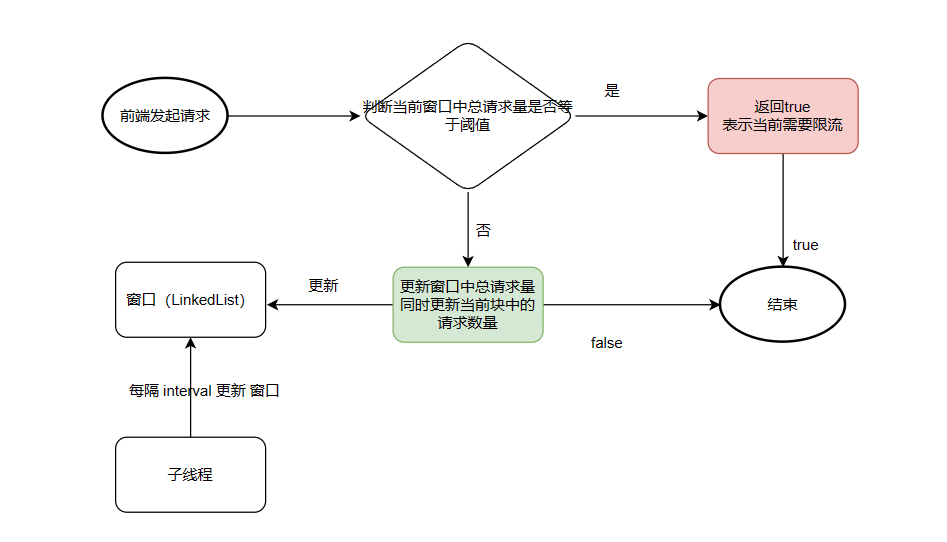
算法的步骤如下:
- 定义时间窗口的长度,例如5分钟。
- 初始化一个长度为窗口大小的队列,用于保存数据。
- 当有新的数据到达时,将其加入队列,并检查队列的长度是否超过窗口大小。
- 如果队列长度超过窗口大小,则移除队首的数据,保持队列长度不变。
- 对队列中的数据进行处理和分析,得出相应的结果。
备注:
- 这里并不是每次更新都去计算从当前块之前的所有块的请求数量,而是但是适用一个变量 count 来记录当前整个窗口的请求数量,这是典型的空间换时间策略,在 ArrasyList源码中也有看到过、
注意事项:
- 由于使用到了多线程技术,这里就很容易出现线程安全问题!
package com.ghp.demo.limiter.impl;import com.ghp.demo.limiter.TrafficLimiter;
import org.springframework.stereotype.Component;import java.util.LinkedList;/*** @author ghp* @title 滑动时间窗口限流器* @description*/
@Component(value = "SlidingTimeWindowLimiter")
public class SlidingTimeWindowLimiter implements TrafficLimiter {// 这个变量,我用来测试的,无关紧要private static int i = 0;/*** 记录整个窗口中接口请求次数*/private int count;/*** 使用 LinkedList 来记录滑动时间窗口中每一个格子中请求的数量*/private LinkedList<Integer> slots = new LinkedList<>();/*** 每秒限流的最大请求数*/private int threshold = 1;/*** 滑动时间窗口里的每个格子的时间长度,单位ms*/private long interval = 100L;/*** 滑动时间窗口里的格子数量,划分的格子越多精度越高* 窗口中格子的数量 和 每个格子的长度 决定了整个滑动时间窗口的大小* 滑动时间窗口的时间跨度是:part * interval*/private int partNum = 10;public SlidingTimeWindowLimiter() {// 初始第一个窗口,第一个窗口中接口的请求数量为0slots.addLast(0);// 定义线程任务,不断循环执行滑动窗口// 滑动过程:最开始添加一个格子(初始化时),然后不断添加格子,当发现格子数量超过窗口// 中最大格子数量,移除窗口中第一个格子,在窗口末尾添加一个格子new Thread(() -> {while (true) {try {// 休眠 100ms,每一个格子的时间间隔是 100msThread.sleep(interval);} catch (InterruptedException e) {e.printStackTrace();}// 100ms 后往窗口中添加一个新的块slots.addLast(0);// 判断窗口新增块之后是否超过最大块数量if (slots.size() > partNum) {// 超过窗口中块数量最大限制,移除窗口最开始的那个块,同时更新 countcount -= slots.peekFirst();slots.removeFirst();System.out.printf("移除第%s个格子,此时窗口中接口的请求量为%s\n", i++, count);}}}).start();}/*** 判断是否限流** @return返回 true代表限流,false代表通过*/@Overridepublic synchronized boolean limit() {// 判断是否限流if (((count + 1)) > threshold) {return true;}// 未限流,可以进行接口请求,此时需要更新 当前块中的请求数量 和 窗口当前最大接口请求数slots.set(slots.size() - 1, slots.peekLast() + 1);count++;return false;}
}

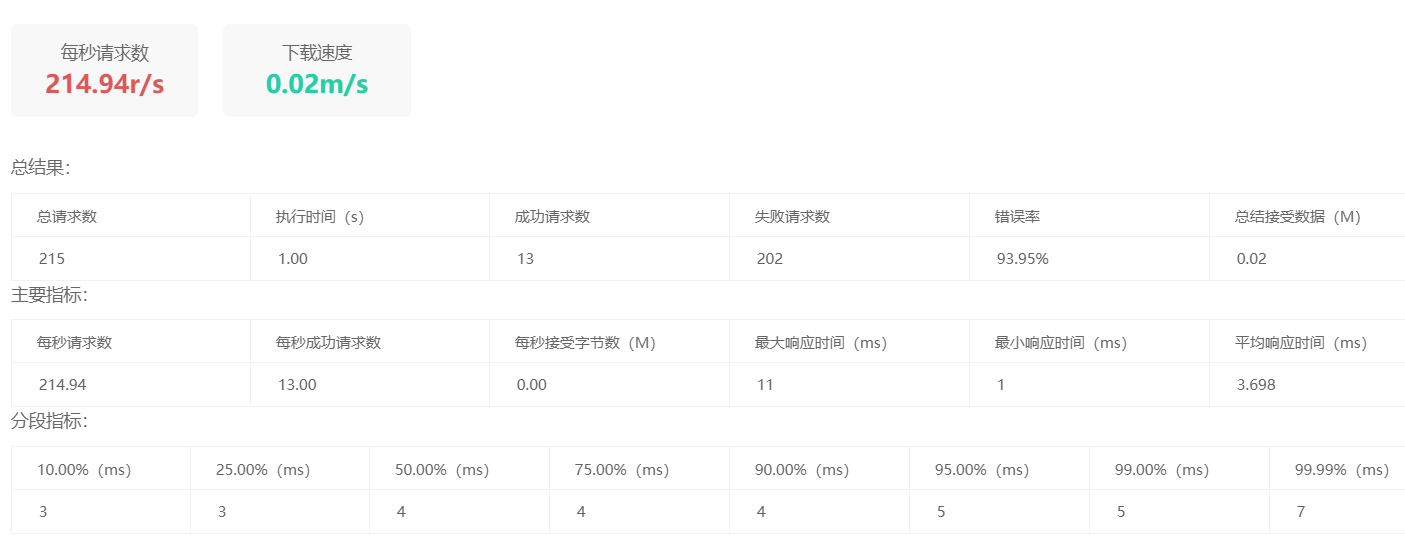
备注:关于窗口的滑动,也可以不需要单独开启一个线程(或定时任务)专门去滑动,可以注解选择通过取模的方式进行窗口滑动
两种方式相比较:
使用取模来实现滑动窗口的限流机制的优点是实现简单、轻量级,不需要额外的线程。它适用于单机场景和低并发的情况下,对系统性能的影响较小。同时,取模操作是原子的,不会出现线程竞争的问题。然而,取模操作的缺点是无法做到精确的限流。由于请求的分布不是非常均匀,可能会导致某个时间窗口内的实际请求超过了限流阈值,而在其他时间窗口内则未超过。这意味着在某些情况下,可能会导致请求被错误地拒绝或者允许通过。相比之下,使用单独的线程实现限流可以更精确地控制请求的速率。通过定时任务、令牌桶等机制,可以实现更细粒度的限流控制。然而,这种方式会引入额外的线程开销和系统资源消耗,对系统的性能和可伸缩性有一定的影响。
最后还是那句话"具体场景具体分析"🤣,具体来说如果你的系统平均并发量(也就是并发量高的次数特别少,平常都是比较低的并发量)可以选择取模实现滑动窗口;如果你的系统常年处在高并发的状况,并且你需要更加精确、实时地进行流量控制,此时就可以选择单独开一个线程或定时任务实现窗口滑动
漏桶限流算法
漏桶限流算法相关介绍
漏桶限流算法(Leaky Bucket Algorithm)是一种常用的网络流量控制算法,用于平衡系统的吞吐量和请求的到达速率。它可以有效地限制流量的峰值和平均速率,防止系统过载和拥塞。
-
漏桶限流算法基本原理:
- 漏桶是一个固定容量的桶,类似于水桶,有一个固定的大小和漏水速率。
- 请求到达时,将放入漏桶中,如果漏桶已满,则丢弃该请求。
- 桶以固定速率漏水,即按照一定的速率处理请求,这个速率决定了系统的吞吐量。
- 如果桶中有请求等待处理,那么就按照顺序处理请求,并从漏桶中移除相应数量的请求。
-
漏桶限流算法的特点:
- 平滑控制流量:通过漏桶的漏水速率,平滑了请求的到达速率,避免了突发流量对系统的影响。
- 丢弃超出容量的请求:当漏桶已满时,新的请求会被丢弃,从而保护系统免受过多请求的压力。
- 控制请求的处理速率:漏桶以固定速率处理请求,限制了系统的吞吐量,防止系统被过多的请求拖垮
-
漏桶限流算法的优缺点:
- 优点:
- 平滑流量:漏桶以固定速率处理请求,平滑了请求的到达速率,避免了突发流量对系统的影响。
- 控制吞吐量:漏桶限制了系统的吞吐量,可以根据系统的处理能力和资源情况进行合理控制,避免过载。
- 保护系统稳定:通过丢弃超出容量的请求,漏桶限流算法可以保护系统免受过多请求的压力,防止系统崩溃或资源耗尽。
- 缺点:
- 延迟增加:当有大量请求等待处理时,漏桶限流算法可能会引入一定的延迟,导致请求的响应时间增加。
- 对突发流量不敏感:漏桶限流算法对于突发流量的处理相对较为固定,无法灵活地应对突发性的高流量情况。
- 优点:
-
漏桶限流算法的适用场景:
- 网络流量控制:在网络中,可以使用漏桶限流算法来平滑请求的到达速率,避免网络拥塞和过载,保证系统的稳定性。
- 服务质量管理:漏桶限流算法可以用于QoS(Quality of Service)管理,确保关键服务和资源优先得到响应,提高用户体验。
- 防止恶意攻击:通过限制请求的速率,漏桶限流算法可以防止恶意攻击者发送大量请求,保护后端系统免受压力和拒绝服务(DDoS)攻击。
- 平滑处理峰值流量:对于突发的高流量情况,漏桶限流算法可以平滑处理,避免系统被瞬时的大量请求拖垮。
下面这张图十分形象地描述了这个算法:
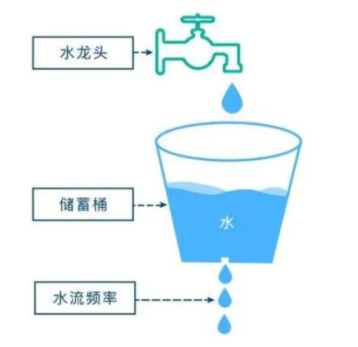
备注:关于桶容量的设置,主要有两种方式
- 方式一:一种常见的实现方式是将漏桶的初始容量设置为最大值,也就是表示初始状态下桶是空的,不包含任何请求。这样,在系统启动时或者限流策略重置时,桶会被填满到最大容量,然后按照请求的到达速率进行漏水处理。
- 方式二:另一种实现方式是将漏桶的初始容量设置为0,也就是表示初始状态下桶是满的,已经包含了最大容量的请求。这样,在系统启动时或者限流策略重置时,需要等待桶中的请求数量逐渐减少,才能开始接受新的请求。
相较于两种策略,方式二可能更加安全
漏桶限流算法实现
具体的实现步骤:
- 定义漏桶容量和漏水速率:确定漏桶的容量和漏水速率,这两个参数决定了系统的吞吐量和请求处理能力。
- 初始化漏桶状态:创建一个漏桶数据结构,并将其初始化为空(即没有请求等待处理)。
- 请求到达时的处理:
- 检查漏桶是否已满:判断漏桶中当前的请求数量是否已达到漏桶的容量。如果已满,则丢弃该请求。
- 添加请求到漏桶:如果漏桶未满,将新的请求添加到漏桶中等待处理。
- 漏桶漏水:以固定速率的漏水过程,即按照一定的时间间隔从漏桶中移除一定数量的请求。可以使用定时器或者线程来实现漏水操作。
- 处理漏桶中的请求:检查漏桶中是否有请求需要处理。如果有请求,则按照顺序处理请求,并从漏桶中移除相应数量的请求。
- 重复步骤3-5:重复执行步骤3到步骤5,持续地接收和处理请求,以达到限制流量的目的。
package com.ghp.demo.limiter.impl;import com.ghp.demo.limiter.TrafficLimiter;
import org.springframework.stereotype.Component;/*** @author ghp* @title 漏桶限流器* @description*/
@Component(value = "LeakyBucketLimiter")
public class LeakyBucketLimiter implements TrafficLimiter {// 这个变量,我用来测试的,无关紧要private static int i = 1;/*** 桶起始时间*/private long start = System.currentTimeMillis();/*** 桶的容量,桶最大能够接收的请求数量*/private long capacity = 10L;/*** 水漏出的速率 10个请求/s(也就是每秒系统能处理的请求数)*/private long rate = 1;/*** 当前水量(当前桶中累积请求数)*/private long water = 0;/*** 判断是否限流** @return返回 true代表限流,false代表通过*/public synchronized boolean limit() {// 计算桶漏掉水之后还剩余的水(剩余的水就算还可以接收请求的数量)long now = System.currentTimeMillis();water = Math.max(0, water - ((now - start) / 1000) * rate);// 更新初始位置 startstart = now;// 判断当前的水有没有超过桶的最大容量System.out.printf("第%s次请求,当前桶中的水%s\n" , i++, water);if ((water + 1) <= capacity) {water++;return false;} else {return true;}}
}

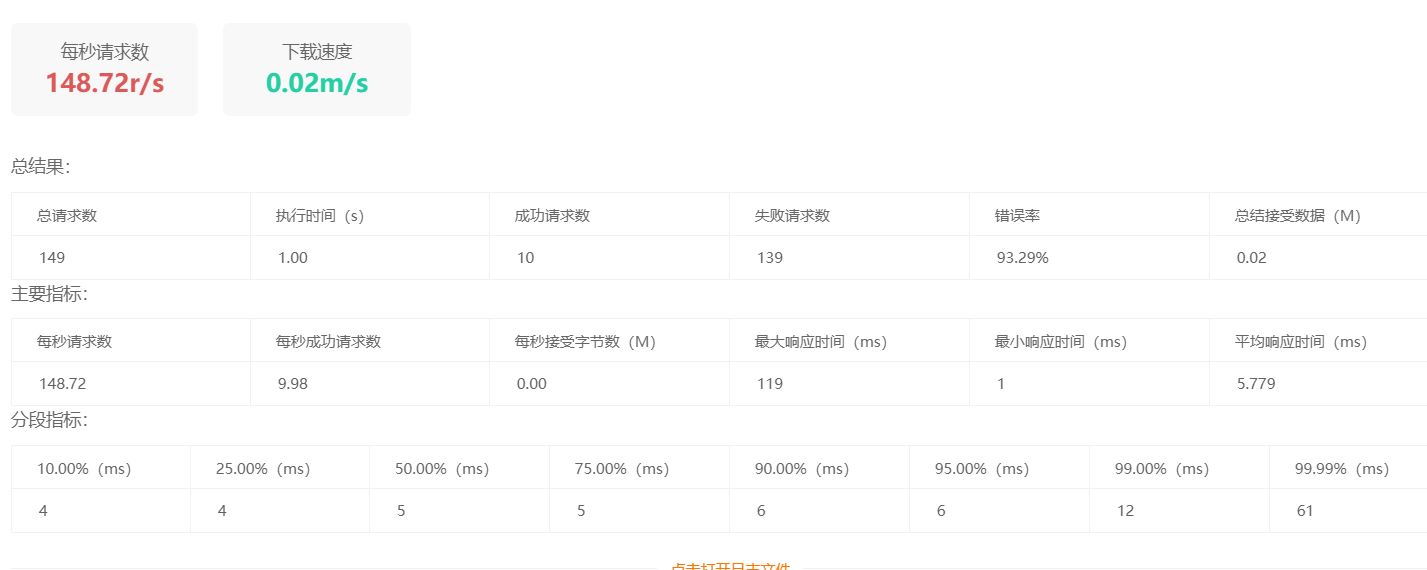
我设置qps为10时,压测情况:
令牌桶限流算法
令牌桶限流算法相关介绍
令牌桶算法(Token Bucket Algorithm)也是一种常用的网络流量控制算法,用于平滑限制请求的到达速率。与漏桶限流算法类似,令牌桶算法可以有效地控制系统的吞吐量和请求处理能力。
- 令牌桶限流算法的特点
- 平滑控制流量:令牌桶以固定速率产生令牌,通过控制令牌的生成速度,平滑了请求的到达速率。
- 灵活应对突发流量:当桶中有足够的令牌时,可以处理突发的大量请求;当桶中没有令牌时,可以限制请求的到达速率。
- 控制请求处理速率:通过调整令牌产生的速率,可以控制系统的吞吐量和请求处理能力。
- 令牌桶算法的优缺点:
- 优点:
- 精确控制流量:通过控制令牌的生成速率和桶中令牌的数量,可以精确地控制系统的吞吐量和请求处理速率。
- 支持突发流量:当桶中有足够的令牌时,可以支持短时间内的高流量,提高系统的处理能力。
- 灵活性:可以根据实际需求灵活调整令牌产生的速率和桶的容量,适应不同场景的流量控制要求。
- 缺点:
- 响应时间延迟:当桶中没有足够的令牌时,请求需要等待直到有令牌可用,可能导致请求的响应时间延迟。
- 复杂性:相对于漏桶限流算法而言,令牌桶算法稍微复杂一些,需要维护令牌桶的状态和生成令牌的速率。
- 优点:
- 令牌桶算法的适用场景
- 网络流量控制:在网络中,可以使用令牌桶算法来限制请求的到达速率,保护系统免受过多请求的冲击,防止网络拥塞和资源耗尽。
- 服务质量管理:令牌桶算法可用于QoS(Quality of Service)管理,确保关键服务和资源优先得到响应,提高用户体验。
- 平滑限制请求速率:通过调整令牌产生的速率和桶中令牌的数量,令牌桶算法可以平滑地限制请求的到达速率,避免突发流量对系统的影响。
- 控制资源访问频率:在需要限制对特定资源的访问频率时,令牌桶算法可以控制请求的处理速率,保证资源的稳定和有效利用。
- 防止恶意攻击:通过限制请求的速率,令牌桶算法可以防止恶意攻击者发送大量请求,保护后端系统免受压力和拒绝服务(DDoS)攻击。
令牌桶限流算法实现

令牌桶算法具体实现步骤:
-
定义一个令牌桶,其中包含固定数量的令牌,每个令牌表示一个请求的通行权。
-
以固定的速率产生令牌,并存放到令牌桶中,即不断地往桶里添加令牌。
-
当有请求到达时,需要从令牌桶中获取一个令牌:
-
1 如果桶中还有令牌,则可以处理该请求,并从桶中取走一个令牌。
-
2 如果桶中没有令牌可用,则拒绝该请求或等待直到有令牌可用。
-
package com.ghp.demo.limiter.impl;import com.ghp.demo.limiter.TrafficLimiter;
import org.springframework.stereotype.Component;/*** @author ghp* @title 令牌桶限流器* @description*/
@Component(value = "TokenBucketLimiter")
public class TokenBucketLimiter implements TrafficLimiter {// 这个变量,我用来测试的,无关紧要private static int i = 1;/*** 开始时间(用于记录上一次请求的时间)*/private long start = System.currentTimeMillis();/*** 桶的容量,也就是一次最大可以接收多少请求*/private long capacity = 10;/*** 令牌放入速度,也就是系统能够处理请求的速率* 当前速率为 1,也就是每秒钟往令牌桶中放入一个令牌*/private long rate = 1;/*** 当前令牌数量*/private long tokens = 0;/*** 判断是否限流** @return返回 true代表限流,false代表通过*/@Overridepublic synchronized boolean limit() {long now = System.currentTimeMillis();// 计算当前当前桶中补充后还有多少令牌(这一步和之前的漏桶完全就是反着来的)tokens = Math.min(capacity, tokens + ((now - start) / 1000) * rate);System.out.printf("第%s次请求,当前桶中的令牌数量为%s\n", i++, tokens);// 更新起始时间start = now;// 判断if (tokens < 1) {// 桶中令牌数量不足1,需要限流return true;} else {// 还有令牌,领取令牌tokens--;return false;}}
}

我设置qps为10时,压测情况:

成功抗住了压测,qps设置10,压测成功请求也是10,符合我的预期
Sentinel实现限流
Sentinel 是阿里巴巴开源的一个流量控制和熔断框架,用于解决分布式系统中的限流、熔断和降级等问题,是一个十分成熟的限流解决方案,同时Sentinel 底层集成了四种常见的算法,可以做到限流策略的灵活切换。
当然本文重点是讲限流,关于Sentinel相关详情可以参考下方链接
推荐阅读:
介绍 · alibaba/Sentinel Wiki (github.com)
quick-start | Sentinel (sentinelguard.io)
Sentinel 介绍 - 《Sentinel v1.8 文档手册》 - 书栈网 · BookStack
-
Step1:控制台jar包下载地址:Tags · alibaba/Sentinel (github.com)
-
Step2:进入 cmd 窗口,运行下面指令即可启动控制台
# 方式一;默认启动 java -jar sentinel-dashboard-1.8.6.jar # 方式二:指定端口和IP启动 java -Dserver.port=8081 -Dcsp.sentinel.dashboard.server=127.0.0.1:8081 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.6.jar备注:要想要后台启动,可以使用
nohup指令,示例:nohup [java -jar sentinel-dashboard-1.8.6.jar] &,然后通过jps指令查看是否启动成功 -
Step3:浏览器访问
http://IP:8080/
默认的用户名和密码是 sentinel
-
Step4:构建Maven工程
1)依赖
<!--Web环境--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2.4.2</version></dependency><!--SpringCloud整合Sentinel--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId><version>2021.1</version></dependency>2)配置文件
server:port: 10086spring:application:name: sentinel-democloud:sentinel:transport:dashboard: localhost:8080 #控制台的地址3)测试代码
package com.ghp.demo.controller;import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController;@RestController public class HelloController {public static int count = 0;@GetMapping("/hello")public String hello() {System.out.printf("接口被访问%s次\n", count++);return "Hello world!";}} -
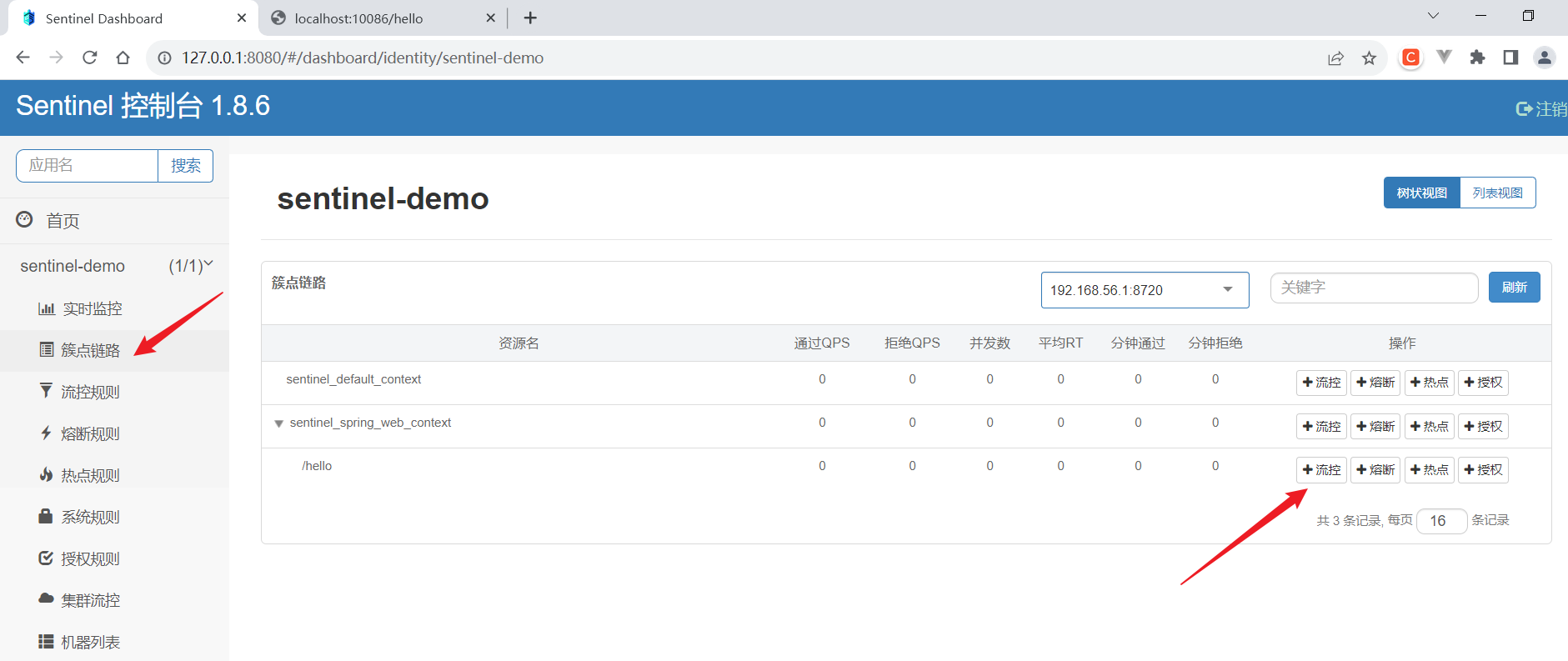
Step5:配置限流

此外还可以配置高级选项:
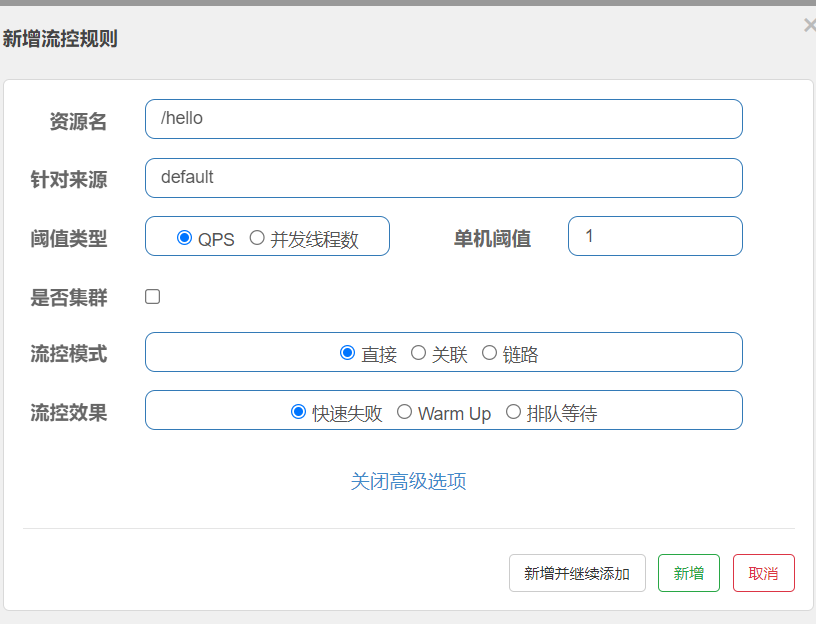
1)快速失败,当求情达到阈值时,直接抛出异常Blocked by Sentinel(flow limiting),服务器返回状态码429
快速失败,默认流控效果是快速失败,也就是访问超过的流量直接返回失败信息
2)Warm Up,预热流控效果,如果设置单机阈值为10,并不是一开始 1秒中就能够访问 10个请求,而是一开始只放行少量请求,然后慢慢得达到 每秒10个请求,选中 Warm Up 可以自己选定预热时长,如果 预热时长是 10 秒钟,那么一开始可能就只能访问 1次,第二秒访问两次,到第 10秒才能1秒访问10次
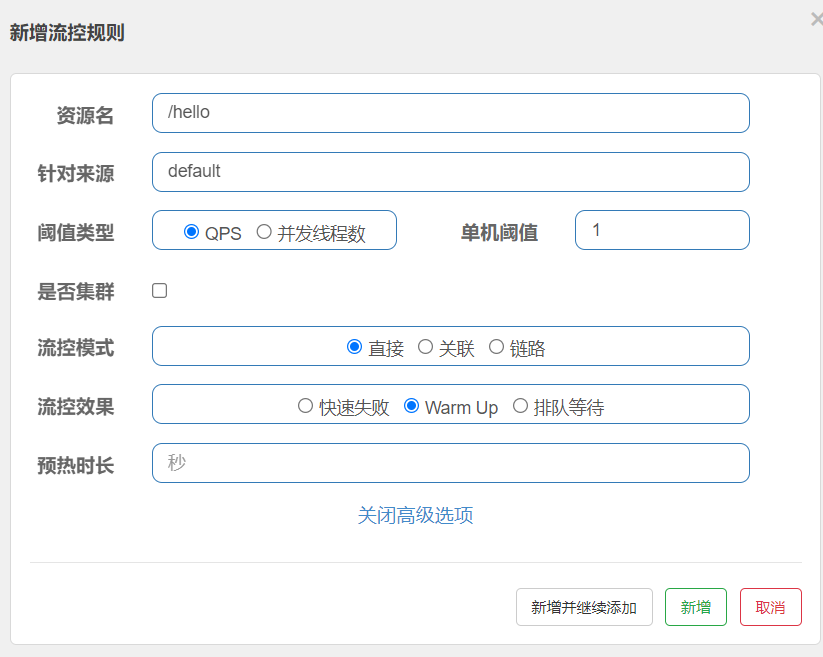
备注:默认最开始的阈值是
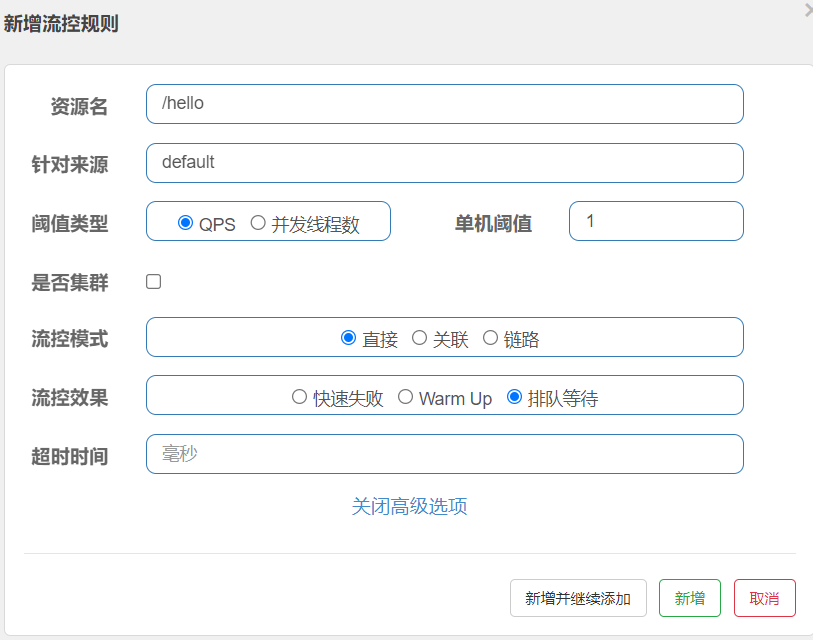
threshold/3,如果阈值是 10,一开始一秒只能访问 10/3≈3 个请求3)排队等待,超过阈值的直接进入等待队列,这个可以配置超时时间,如果排队的请求超过了这个超时时间,就会返回失败信息。
比如:我们阈值设置为1,超时时间设置为10s,此时我们一秒发送100个请求,最终能够成功处理的请求十多个请求
Guava实现限流
谷歌提供了名为Guava的开源Java库,其中包含了一个RateLimiter类,用于实现速率限制功能。
Google Guava的RateLimiter是基于令牌桶算法实现的。使用RateLimiter可以控制在一定时间内允许执行的操作次数或单位时间内允许执行的操作的频率。
-
Step1:引入依赖
<!--Guava工具包--><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>31.1-jre</version></dependency> -
Step2:编码
@Overridepublic boolean limit() {RateLimiter rateLimiter = rateLimiterMap.computeIfAbsent(methodName, k ->RateLimiter.create(10));// 判断请求是否限流if (!rateLimiter.tryAcquire()) {// 限流return true;}return false;}
我设置qps为10时,压测结果:
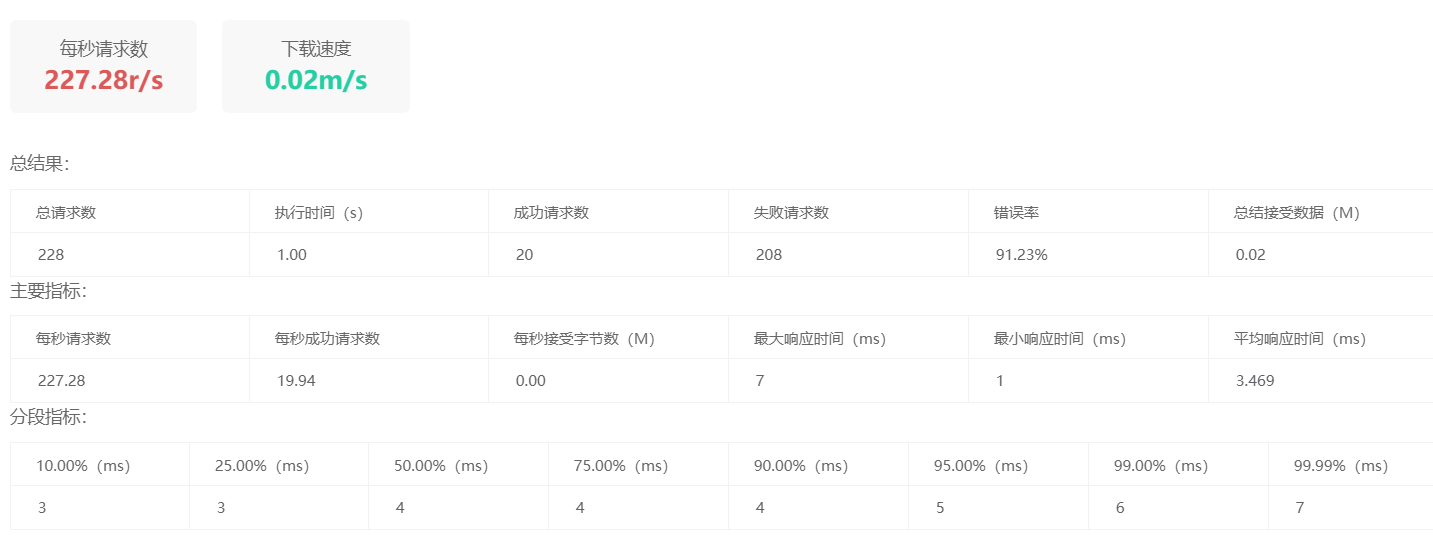
最终测试,可以发现并没有扛住压力测试,我qps设置的是10,但是最终成功请求数居然是20!结果并不符合我的预期
总结
- 限流算法的实现
- 计数器限流算法
- 固定窗口:实现简单且维护性较高,但是无法处理突发流量,并且灵活性不高,误差较大,最高峰QPS可能是设置值的2倍,同时无法适用于分布式环境(但是可以改造成Redis计数器,就能够利用Redis适应分布式环境)
- 滑动窗口:实现较为复杂,可维护性不高,需要特别注意线程安全问题,灵活性较高,但是对于滑动窗口最小块的大小选择比较困难,块小内存高,块大精确度低,需要不断测试才能找到最优解,同样无法直接适用于分布式环境(需要改造)
- 桶限流算法
- 漏桶:实现较为复杂、可维护性不高,对于流量的限制过于平滑,无法处理突发流量
- 令牌桶:实现复杂、可维护性不高,它相当于是漏桶的改良(漏桶是做减法,令牌桶是做加法),能够一定程度上应对突发流量,这个很像RabbitMQ的削峰填谷特点(推荐使用)
- 计数器限流算法
总的来讲:
- 如果你的系统很简单,也不想搞得很复杂,对流量的控制不需要那么的准确推荐适用固定窗口;
- 如果想要控制比较精确,就可以选择适用滑动窗口;
- 如果系统比较复杂,想要比较平滑的流控,则可以选用漏桶;
- 如果系统是处于分布式环境,我建议可以直接使用第三方成熟的解决方案,比如:Sentinel、Guava、Resilience4j等,都是十分优秀的限流解决方案
最后来一句万金油的话“最终系统选择使用哪一种限流策略,具体情况具体分析”,关于限流策略中的哪些参数选择,比如:固定窗口的大小,滑动窗口中滑块的大小,漏桶的容量、漏水的速率、令牌桶的大小、令牌的生成速率,还有如何确保线程安全,这些东西都是特别需要仔细斟酌的(可以结合做压力测试做最终的选择)
Bug记录
-
bug1:启动项目报循环依赖问题
The dependencies of some of the beans in the application context form a cycle:org.springframework.boot.autoconfigure.web.servlet.WebMvcAutoConfiguration$EnableWebMvcConfiguration ┌─────┐ | com.alibaba.cloud.sentinel.SentinelWebAutoConfiguration (field private java.util.Optional com.alibaba.cloud.sentinel.SentinelWebAutoConfiguration.sentinelWebInterceptorOptional) └─────┘问题原因:SpringBoot版本与SpringCloud版本冲突。
我项目中使用的是 SpringBoot2.7版本的 Web依赖,而引入的SpringCloud是2021.1,版本对应关系参考下方这张图:

问题解决:将SpringBoot版本从 2.7.2 修改为 2.4.2
-
bug2:自定义SDK后,第三方项目引入结果注解不生效
问题原因:由于当前项目的包路径和SDK中Bean的跑路径不同,导致SDK中的Bean没有被Spring加载到 IOC 容器中
问题解决:在第三方项目中添加
@Important(RequestLimitConfig.class),这样就能够导入SDK的配置类,然后在SDK的配置类中添加@ComponentScan注解,这样就能够成功引入SDK了
参考文章
- 面试必备:4种经典限流算法讲解 - 知乎 (zhihu.com)
- 限流之计数器算法-CSDN博客
- 深入理解 Sentinel 中的限流算法 - 知乎 (zhihu.com)
- 谷歌Guava限流工具RateLimiter - 知乎 (zhihu.com)
- 一文搞懂高频面试题之限流算法,从算法原理到实现,再到对比分析 - 知乎 (zhihu.com)
- 关于滑动时间窗口算法 - 知乎 (zhihu.com)
分布式需求:是指同一个接口的服务部署在多个不同的节点(服务器)上,状态需要跨越节点实现共享 ↩︎