react 的 render 阶段,其中
begin时会调用reconcileChildren函数,reconcileChildren中做的事情就是 react 知名的 diff 过程
diff 算法介绍
react 的每次更新,都会将新的 ReactElement 内容与旧的 fiber 树作对比,比较出它们的差异后,构建新的 fiber 树,将差异点放入更新队列之中,从而对真实 dom 进行 render。简单来说就是如何通过最小代价将旧的 fiber 树转换为新的 fiber 树。
diff 策略
react 将 diff 算法优化到 O(n) 的时间复杂度,基于了以下三个前提策略:
- 只对同级元素进行比较。如果出现跨层级的 dom 节点更新,则不进行复用。 深度优先遍历
- 两个不同类型的组件会产生两棵不同的树形结构。类型不同,整个删除
- 对同一层级的子节点,开发者可以通过
key来确定哪些子元素可以在不同渲染中保持稳定。
上面的三种 diff 策略,分别对应着 tree diff、component diff 和 element diff。
tree diff
根据策略一,react 会对 fiber 树进行分层比较,只比较同级元素(同一个父节点下的子节点(往上的祖先节点也都是同一个),而不是树的深度相同)。

react 的 tree diff 是采用深度优先遍历,所以要比较的元素向上的祖先元素都会一致,
即图中会对相同颜色的方框内圈出的元素进行比较,例如左边树的 A 节点下的子节点 C、D 会与右边树 A 节点下的 C、D、E进行比较。
当元素出现跨层级的移动时,例如下图:

A 子树从 root 节点下到了 B 节点下,在 react diff 过程中并不会直接将 A 子树移动到 B 子树下,而是进行如下操作:
- 在 root 节点下删除 A 节点
- 在 B 节点下创建 A 子节点
- 在新创建的 A 子节点下创建 C、D 节点
component diff
对于组件之间的比较,只要它们的类型不同,就判断为它们是两棵不同的树形结构,直接会将它们给替换掉。
例如下面的两棵树,左边树 B 节点和右边树 K 节点除了类型不同(比如 B 为 div 类型,K 为 p 类型),内容完全一致,但 react 依然后直接替换掉整个节点。实际经过的变换是:
- 在 root 节点下创建 K 节点
- 在 K 节点下创建 E、F 节点
- 在 F 节点下创建 G、H 节点
- 在 root 节点下删除 B 子节点

虽然如果在本例中改变类型复用子元素性能会更高一点,但是在时机应用开发中类型不一致子内容完全一致的情况极少,对这种情况过多判断反而会增加时机复杂度,降低平均性能。
element diff
react 对于同层级的元素进行比较时,会通过 key 对元素进行比较以识别哪些元素可以稳定的渲染。同级元素的比较存在插入、删除和移动三种操作。
如下图左边的树想要转变为右边的树:

实际经过的变换如下:
- 将 root 节点下 A 子节点移动至 B 子节点之后
- 在 root 节点下新增 E 子节点
- 将 root 节点下 C 子节点删除

结合源码看 diff
整体流程
diff 算法从 reconcileChildren 函数开始,根据当前 fiber 是否存在,决定是直接渲染新的 ReactElement 内容还是与当前 fiber 去进行 Diff,看一下其源码:
// 如果当前 fiber 节点为空,则直接将新的 ReactElement 内容生成新的 fiber,使mountChildFibers函数
// 当前 fiber 节点不为空,则与新生成的 ReactElement 内容进行 diff 使用reconcileChildFibers函数
export function reconcileChildren(current: Fiber | null, // 当前 fiber 节点workInProgress: Fiber, // 父 fibernextChildren: any, // 新生成的 ReactElement 内容renderLanes: Lanes, // 渲染的优先级
) {if (current === null) {// 如果当前 fiber 节点为空,则直接将新的 ReactElement 内容生成新的 fiberworkInProgress.child = mountChildFibers(workInProgress,null,nextChildren,renderLanes,);} else {// 当前 fiber 节点不为空,则与新生成的 ReactElement 内容进行 diffworkInProgress.child = reconcileChildFibers(workInProgress,current.child,nextChildren,renderLanes,);}
}
因为我们主要是要学习 diff 算法,所以我们暂时先不关心 mountChildFibers 函数,主要关注 reconcileChildFibers ,我们来看一下它的源码
j入口函数中,接收 returnFiber、currentFirstChild、newChild、lanes 四个参数,其中,根据 newChid 的类型,我们主要关注几个比较常见的类型的 diff,单 React 元素的 diff、纯文本类型的 diff 和 数组类型的 diff。
// 对新创建的 ReactElement 最外层是 fragment 类型单独处理,比较其 children
// 对更新后的 React.Element 是单节点的处理
// 更新后的 React.Element 是多节点的处理
// 不符合以上情况都视为 empty,直接从父节点删除所有旧的子 Fiber
所以根据 ReactElement 类型走的不同流程如下:

新内容为单元素
当新创建的节点 type 为 object 时,我们看一下其为 REACT_ELEMENT_TYPE 类型的 diff,即 placeSingleChild(reconcileSingleElement(...)) 函数。
先看一下 reconcileSingleElement 函数的源码:
echarts原理和源码解析 - 掘金 (juejin.cn)
根据源码得知,reconcileSingleElement 函数中,会遍历父 fiber 下所有的旧的子 fiber,寻找与新生成的 ReactElement 内容的 key 和 type 都相同的子 fiber。每次遍历对比的过程中:
- 若当前旧的子 fiber 与新内容 key 或 type 不一致,对当前旧的子 fiber 添加
Deletion副作用标记(用于 dom 更新时删除),继续对比下一个旧子 fiber - 若当前旧的子 fiber 与新内容 key 或 type 一致,则判断为可复用,通过
deleteRemainingChildren对该子 fiber 后面所有的兄弟 fiber 添加Deletion副作用标记,然后通过useFiber基于该子 fiber 和新内容的 props 生成新的 fiber 进行复用,结束遍历。
若都遍历完没找到与新内容 key 或 type 子 fiber,此时父 fiber 下的所有旧的子 fiber 都已经添加了 Deletion 副作用标记,通过 createFiberFromElement 基于新内容创建新的 fiber 并将其 return指向父 fiber。
再来看 placeSingleChild 的源码:
placeSingleChild 中做的事情更为简单,就是将 reconcileSingleElement 中生成的新 fiber 打上 Placement 的标记,表示 dom 更新渲染时要进行插入。
所以对于 REACT_ELEMENT_TYPE 类型的 diff 总结如下:

新内容为纯文本类型
当新创建节点的 typeof 为 string 或者 number 时,表示是纯文本节点,使用 placeSingleChild(reconcileSingleTextNode(...)) 函数进行 diff。
placeSingleChild 前面说过了,我们主要看 reconcileSingleTextNode 的源码:
新内容为纯文本时 diff 比较简单,只需要判断当前父 fiber 的第一个旧子 fiber 类型:
- 当前 fiber 也为文本类型的节点时,
deleteRemainingChildren对第一个旧子 fiber 的所有兄弟 fiber 添加Deletion副作用标记,然后通过useFiber基于当前 fiber 和 textContent 创建新的 fiber 复用,将其 return 指向父 fiber - 否则通过
deleteRemainingChildren对所有旧的子 fiber 添加Deletion副作用标记,然后createFiberFromText创建新的文本类型 fiber 节点,将其 return 指向父 fiber
所以对文本类型 diff 的流程如下:

新内容为数组类型
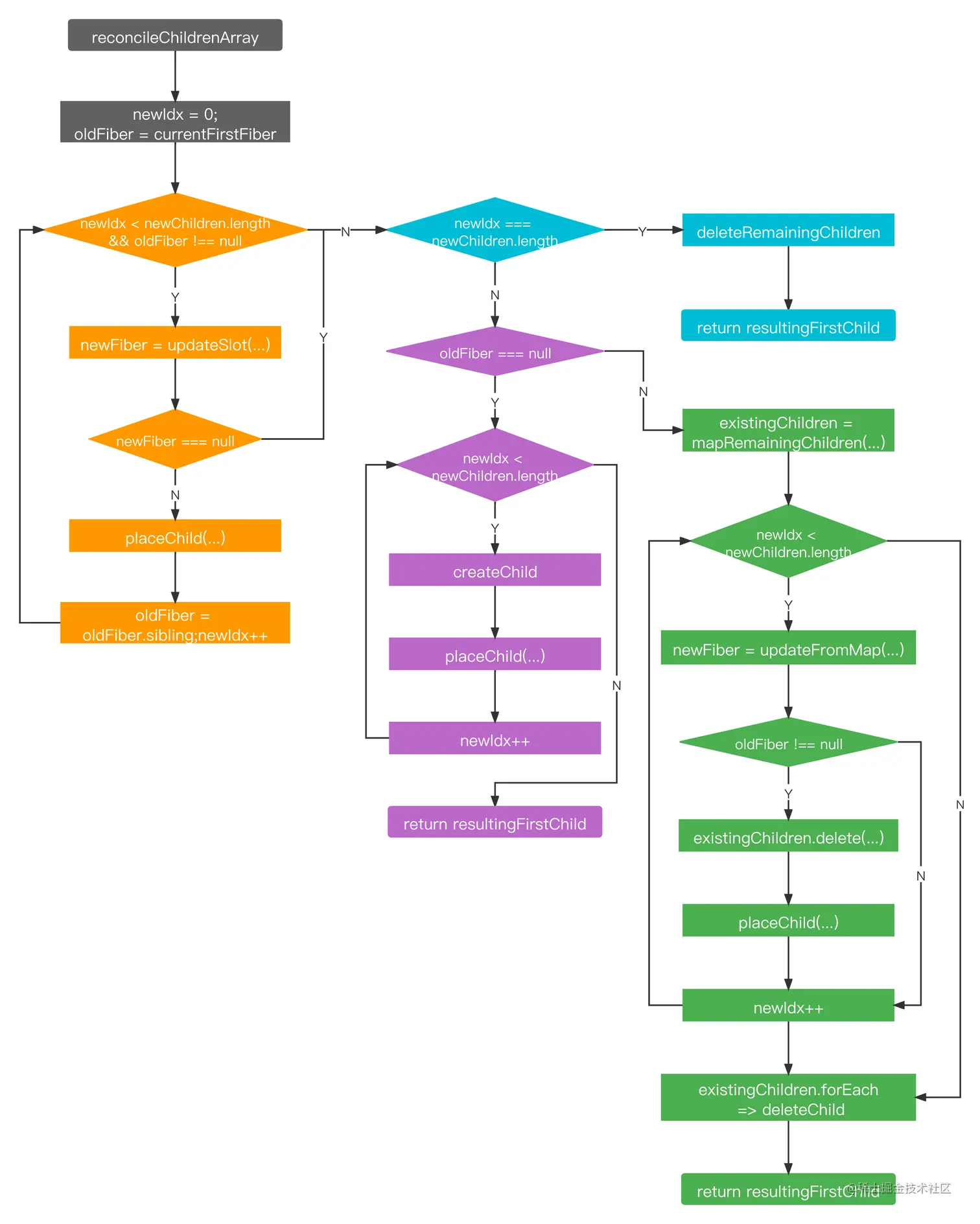
上面所说的两种情况,都是一个或多个子 fiebr 变成单个 fiber。新内容为数组类型时,意味着要将一个或多个子 fiber 替换为多个 fiber,内容相对复杂,我们看一下 reconcileChildrenArray 的源码:
从上述代码我们可以得知,对于新增内容为数组时,react 会对旧 fiber 和 newChildren 进行遍历。
- 首先先对 newChildren 进行第一轮遍历,将当前的 oldFiber 与 当前 newIdx 下标的 newChild 通过
updateSlot进行 diff,diff 的流程和上面单节点的 diff 类似,然后返回 diff 后的结果:- 如果 diff 后 oldFiber 和 newIdx 的 key 和 type 一致,说明可复用。根据 oldFiber 和 newChild 的 props 生成新的 fiber,通过
placeChild给新生成的 fiber 打上Placement副作用标记,同时新 fiber 与之前遍历生成的新 fiber 构建链表树关系。然后继续执行遍历,对下一个 oldFiber 和下一个 newIdx 下标的 newFiber 继续 diff - 如果 diff 后 oldFiber 和 newIdx 的 key 或 type 不一致,那么说明不可复用,返回的结果为 null,第一轮遍历结束
- 如果 diff 后 oldFiber 和 newIdx 的 key 和 type 一致,说明可复用。根据 oldFiber 和 newChild 的 props 生成新的 fiber,通过
- 第一轮遍历结束后,可能会执行以下几种情况:
- 若 newChildren 遍历完了,那剩下的 oldFiber 都是待删除的,通过
deleteRemainingChildren对剩下的 oldFiber 打上Deletion副作用标记 - 若 oldFiber 遍历完了,那剩下的 newChildren 都是需要新增的,遍历剩下的 newChildren,通过
createChild创建新的 fiber,placeChild给新生成的 fiber 打上Placement副作用标记并添加到 fiber 链表树中。 - 若 oldFiber 和 newChildren 都未遍历完,通过
mapRemainingChildren创建一个以剩下的 oldFiber 的 key 为 key,oldFiber 为 value 的 map。然后对剩下的 newChildren 进行遍历,通过updateFromMap在 map 中寻找具有相同 key 创建新的fiber(若找到则基于 oldFiber 和 newChild 的 props创建,否则直接基于 newChild 创建),则从 map 中删除当前的 key,然后placeChild给新生成的 fiber 打上Placement副作用标记并添加到 fiber 链表树中。遍历完之后则 existingChildren 还剩下 oldFiber 的话,则都是待删除的 fiber,deleteChild对其打上Deletion副作用标记。
- 若 newChildren 遍历完了,那剩下的 oldFiber 都是待删除的,通过
所以整体的流程如下:
diff 后的渲染
diff 流程结束后,会形成新的 fiber 链表树,链表树上的 fiber 通过 flags 字段做了副作用标记,主要有以下几种:
- Deletion:会在渲染阶段对对应的 dom 做删除操作
- Update:在 fiber.updateQueue 上保存了要更新的属性,在渲染阶段会对 dom 做更新操作
- Placement:Placement 可能是插入也可能是移动,实际上两种都是插入动作。react 在更新时会优先去寻找要插入的 fiber 的 sibling,如果找到了执行 dom 的
insertBefore方法,如果没有找到就执行 dom 的appendChild方法,从而实现了新节点插入位置的准确性
在 completeUnitWork 阶段结束后,react 会根据 fiber 链表树的 flags,构建一个 effectList 链表,里面记录了哪些 fiber 需要进行插入、删除、更新操作,在后面的 commit 阶段进行真实 dom 节点的更新,下一章将详细讲述 commit 阶段。

![【洛谷 P8781】[蓝桥杯 2022 省 B] 修剪灌木 题解(数学)](https://img-blog.csdnimg.cn/direct/dd3e9093e1af4fba9c07f073ab925b5a.png)


![[C语言][PTA基础C基础题目集] strtok 函数的理解与应用](https://img-blog.csdnimg.cn/direct/b2d611dbf9a84bff8a58785027c22487.png)