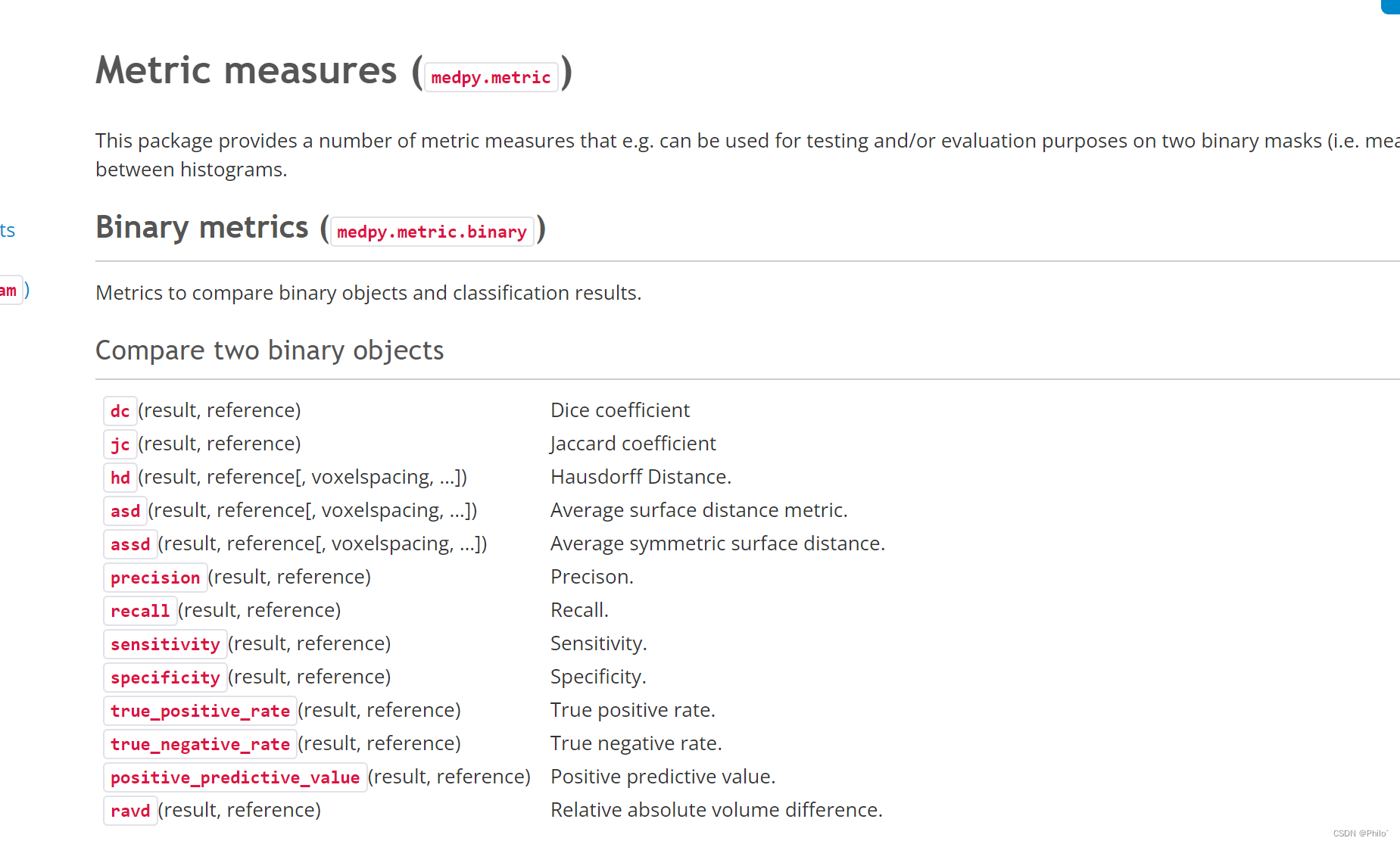
V-Net: 医学图像分割
- V-Net: 医学图像分割
- 引言
- 网络结构
- 训练
- 参考
V-Net: 医学图像分割
引言
卷积网络在计算机视觉和医学图像分析领域有了很广泛的应用。尽管卷积神经网络非常受欢迎,但大多是都是用来处理2D图像,而医学图像却大多是3D的。U-Net是一个全卷积的体数据分割神经网络。它采用端到端的训练方式,包含一个新式的目标函数用于训练时进行优化使用。同时能很好的处理背景和非背景之间的强烈不平衡问题。为了解决数据量有限的问题,使用了非线性变换和直方图匹配的方式来进行数据增强。
网络结构
使用卷积操作来提取数据的特征,于此同时在每个“阶段”的末尾通过合适的步长来降低数据的分辨率。整个结构的左边是一个逐渐压缩的路径,而右边是一个逐渐解压缩的路径。最终输出的大小是和图像原始尺寸一样大的。所有的卷积操作都使用了合适的padding操作。
左边的压缩路径被分为了多个阶段,每个阶段都具有相同的分辨率。每个阶段都包含1到3个卷积层。为了使每个阶段学习一个参数函数:将每阶段的输入和输出进行相加以获得残差函数的学习。结合试验观察得知:这种结构为了确保在短时间内收敛需要一个未曾学过残差函数的相似性网络。
每个阶段的卷积操作使用的卷积核大小为5x5x5。在压缩路径一端,数据经过每个阶段处理之后会通过大小为2x2x2且步长为2的卷积核进行分辨率压缩。因此,每个阶段结束之后,特征图大小减半,这与池化层起着类似的作用。因为图像分辨率降低和残差网络的形式,从而将特征图的通道数进行的翻倍。整个网络结构中,均使用PReLu非线性激活函数。
使用卷积操作替代池化操作,在一些特殊的实现方式下可以在训练过程中减小内存的使用。这是因为在方向传播过程中并不需要像池化操作一样去切换输入和输出之间的映射,同时也更易于理解和分析。
下采样有利于在接下来的网络层中减小输入信号的尺寸同时扩大特征的感受野范围,下一层感受到的特征数量是上一层的两倍。
网络右边部分的功能主要是提取特征和扩展低分辨率的空间支持以组合必要的信息,从而输出一个两通道的体数据分割。这最后一个卷积层使用的卷积核大小是1x1x1,输出的大小与原输入大小一致。两个特征图通过这个卷积层来利用soft-max来生成前景和背景的分割概率图。在右边解压缩路径中每个阶段的最后,通过一个解卷积操作来恢复输入数据的大小。
于此同时,在收缩路径中每阶段的结果都会作为输入的一部分加入到右边解压缩对应的阶段中。这样就能够保留一部分由于压缩而丢失的信息,从而提高最终边界分割的准确性。同时这样有利于提高模型的收敛速度。

训练
损失方式定义为:
D = 2 ⋅ ∑ i N p i g i ∑ i N ( p i 2 + g i 2 ) D=\frac{2\cdot \sum_i^Np_ig_i}{\sum_i^N(p_i^2+g_i^2)} D=∑iN(pi2+gi2)2⋅∑iNpigi
其中, p i p_i pi表示预测的概率, g i g_i gi表示ground truth的概率, N N N表示像素点的个数。
数据增强:
- 使用 2x2x2的网格控制点和B-spline来获得稠密的形变场对图像进行非线性形变。
- 使用直方图匹配来获得不同灰度分布的图像。
参考
[1]:V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation




![[转]医学图像分割综述](https://img-blog.csdnimg.cn/20190730135615475.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDc3OTcyNw==,size_16,color_FFFFFF,t_70)