介绍几篇使用不确定性引导的医学图像分割论文:UA-MT(MICCAI2019),SSL4MIS(MICCAI2021),UG-MCL(AIIM2022).
Uncertainty-aware Self-ensembling Model for Semi-supervised 3D Left Atrium Segmentation, MICCAI2019
解读:学习笔记:Uncertainty-Aware Mean Teacher(UA-MT) - 知乎 (zhihu.com)
半监督3D医学图像分割(二):UA-MT_uncertainty map_宁远x的博客-CSDN博客
论文:https://arxiv.org/abs31907.07034
代码:https://github.com/yulequan/UA-MT
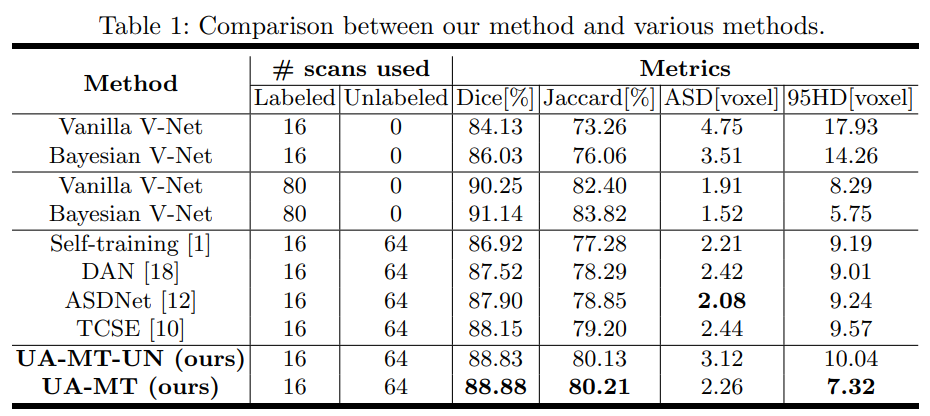
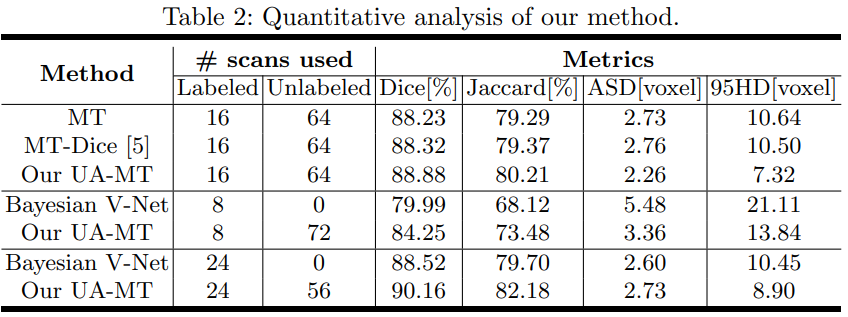
医学图像的分割标签需要专业医师标注,获取代价昂贵,而无标签的数据有很多。半监督学习则是将少量有标注的数据和大量无标注的数据直接输入到网络中,构建一致性损失或者多任务学习,达到比单独用有标注数据集更好的结果。本文提出了一种新的基于不确定性的半监督学习框架(UA-MT),通过额外利用未标记的数据从3D MR图像中分割左心房。和Mean Teacher模型一样,该方法鼓励分割预测在相同输入的不同扰动下保持一致。具体地说,本文建立了一个教师模型和一个学生模型,学生模型通过最小化标注数据上的分割监督损失和所有输入数据上的与教师模型预测输出的一致性损失进行优化。
但未标注的输入中没有提供ground truth,教师模型中的预测目标可能不可靠且有噪声。于是,论文设计了(UA-MT)框架,学生模型通过利用教师模型的不确定性信息,逐渐从有意义和可靠的目标中学习。除了生成目标输出,教师模型还通过Monte Carlo Dropout 估计每个目标预测的不确定性。在估计不确定性的指导下,计算一致性损失时过滤掉不可靠的预测,只保留可靠的预测(低不确定性)。因此,学生模型得到了优化,得到了更可靠的监督,并反过来鼓励教师模型生成更高质量的目标。
简单理解为,本文在Mean-Teacher的基础上,提出不确定性自感知模型(Uncertainty-Aware Self-ensembling Model),将图像加上不同的随机噪声多次输入教师网络中,对输出计算平均概率和不确定度,设计阈值过滤不确定的区域,得到更可靠的预测结果,然后再去指导学生网络。
UA-MT网络结构:不确定性自感知模型(Uncertainty-Aware Self-ensembling Model)
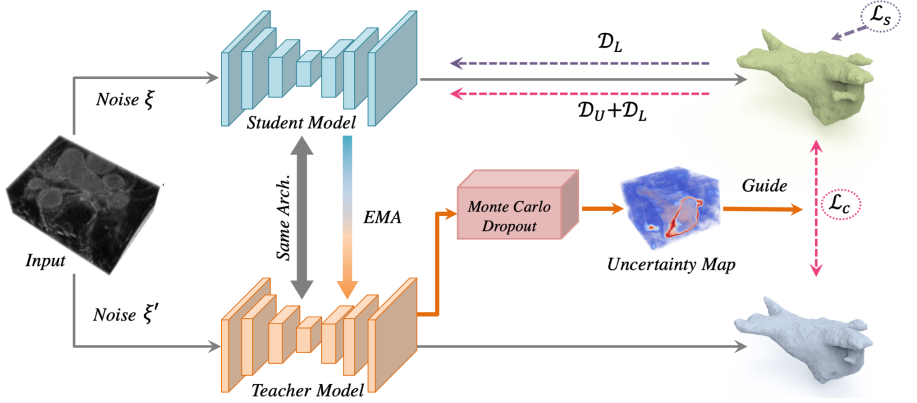
训练过程,教师模型在预测目标的同时评估了每个目标的不确定性。然后利用一致性损失优化学生模型,在不确定度的指导下,更关注不确定度低的区域。
EMA:指数滑动平均 exponential moving average
教师的模型参数不参与反向传播,学生进行有监督学习。
将学生的参数通过滑动平均上传给教师,目的是在迭代次数少时,学生模型不可信,则大多数参数从自己的前一个模型中学习。
Student model: 负责学习
通过最小化分割loss(labeled data)和一致性loss(teacher模型在所有的数据上的输出),通过一致性损失也能给teacher模型一个好的回馈,让他产出高质量的targets。
通过UAMT,只学有用的,可信度高的部分。
Teacher model:在所有数据上预测targets,同时对结果不确定度估计。
和student的输出算一致性损失函数,使得学生的输出和老师一致。teacher的效果只受到一致性损失约束。但是不一定可信且noisy,所以引出需要对uncertainty估计。
估计方法:Monte Carlo sampling
在随机dropout的条件下,T次随机前向传播,能得到T个不同的预测结果,取平均。采用预测熵(predictive entropy)作为估计不确定度的衡量标准,通过阈值过滤不确定的像素。
![]()
(医学图像分割里面大部分用uncertainty都是用的这种T次传播的方式,获取灵活阈值。)
有两种Uncertainty:Aleatoric uncertainty(随机不确定性,也称数据不确定性)和Epistemic uncertainty(认知不确定性,也称模型不确定性)。UA-MT中使用的Monte Carlo Dropout属于Epistemic uncertainty。
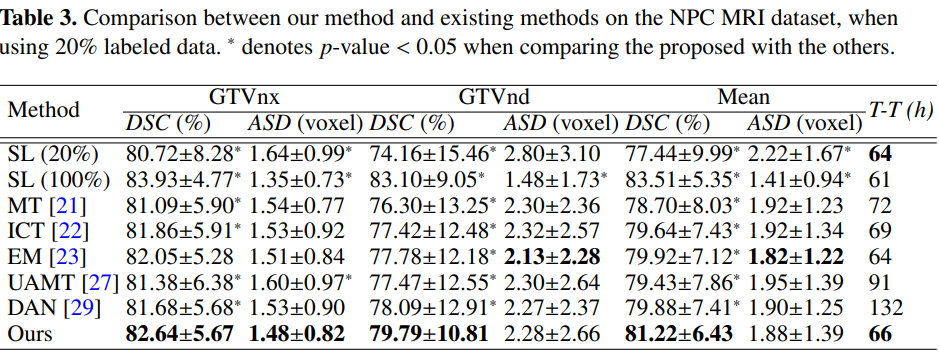
实验:
Efficient Semi-Supervised Gross Target Volume of Nasopharyngeal Carcinoma Segmentation via Uncertainty Rectified Pyramid Consistency, MICCAI2021
解读:【半监督分割】基于不确定性校正金字塔一致性的有效半监督鼻咽癌粗目标分割 - 知乎 (zhihu.com)
半监督3D医学图像分割(三):URPC_宁远x的博客-CSDN博客
Semi-supervise d me dical image segmentation via uncertainty rectified pyramid consistency (译文) - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2012.07042
代码:https://github.com/HiLab-git/SSL4MIS
尽管卷积神经网络(CNN)在许多医学图像分割任务中取得了令人满意的性能,但它们依赖于大量的标记图像进行训练,这需要花费大量的时间来获取。半监督学习已显示出通过从大量未标记图像和有限的标记样本中学习来缓解这一挑战的潜力。这项工作提出了一种用于半监督医学图像分割的简单而有效的一致性正则化方法,称为不确定性校正金字塔一致性(URPC)。选择了一个金字塔预测网络,它可以在不同的尺度上获得一组分割预测。对于半监督学习,URPC通过最小化每个金字塔预测与其平均值之间的差异,从未标记数据中学习。提出了多尺度不确定性校正,以促进金字塔一致性正则化,其中校正试图缓和异常像素的一致性损失,这些异常像素可能具有与平均值显著不同的预测,可能是由于上采样误差或缺乏足够的标记数据。
PPNet框架:
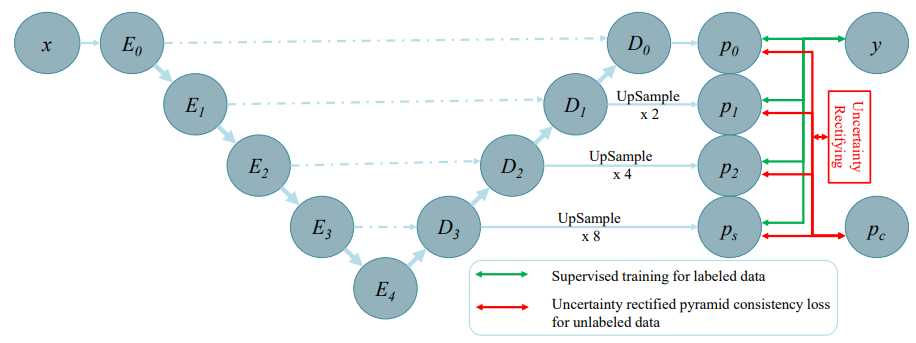
PPNet。在骨干网络的编码器上增加了一个金字塔预测结构。PPNet通过直接最小化监督分割损失来从标记数据中学习。此外,通过金字塔预测之间的多尺度一致性来处理未标记数据。并通过不同尺度之间的差异来进行uncertainty estimation。利用这种不确定性来校正金字塔的一致性。
用于半监督的金字塔预测网络:在解码器的不同分辨率级别添加辅助分割头,以产生不同尺度的预测。
![]()
![]()
- p’是解码器不同层的输出,不同特征的分辨率和通道数是不一样的;
- g由上采样模块、 1x1x1的卷积层和softmax层组成;
- p是概率图(C x H x W x D),此时分辨率和通道数都相同。
有标签数据的损失为:
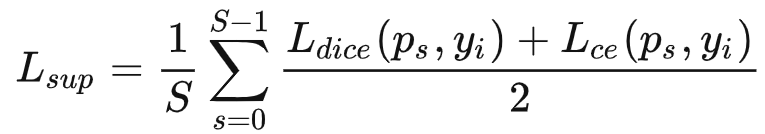
对于未标记数据,通过鼓励多尺度预测相似来引入一致性正则化。具体而言,设计一个金字塔一致性损失,以最小化不同尺度预测之间的差异(即方差)。首先,对这些预测结果求平均:
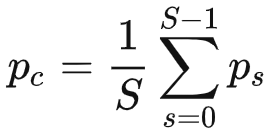
金字塔一致性损失定义为:
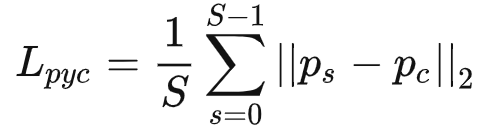
Ps是不同尺度的预测结果,Pc是均值,鼓励在每个尺度的预测和平均预测之间最小化 L2距离。
校正金字塔一致性的不确定性:U-Net网络中,分辨率越低的特征图,通道数越多,语义特征越高级,捕获的低频信息越多。反之,分辨率越高的特征,包含的高频信息越多。由于不同特征的频率信息不同,直接上采样后计算一致性可能存在问题,例如精细细节的丢失或模型崩溃。与UA-MT不同,本文只需要一次前向传播,能够高效的计算不确定度,用的是KL散度计算预测结果和平均预测结果之间的差异。
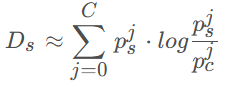
- C是分割类别,
是ps的第j个通道,
是pc的第j个通道;
- Ds是ps和pc之间的KL散度,用来表示不确定度,形状是 C x H x W x D;
- pc可以认为是多尺度预测结果的中心,Ds越大代表离中心越远,不确定性越高。
不确定性修正: 使用估计的不确定性自动选择可靠的体素进行损失计算。修正后的金字塔一致性损失公式为:
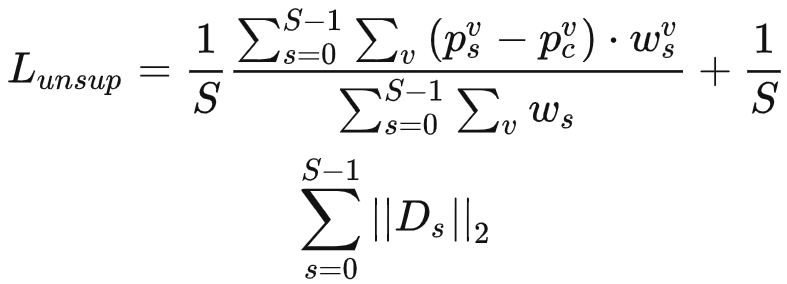
和
分别表示ps和pc在体素v处的概率向量;
- 上式第一项是修正后的金字塔一致性损失,第二项有点像正则化,用来降低不确定性;
和
是当前体素的权重和不确定度,根据公式,不确定度越高的区域,分配的权重越低。
整体损失:URPC在有标注图像上的分割损失和无标注图像上的一致性损失。
![]()
![]()
- Lsup和Lunsup对应有监督损失和无监督损失;
- λ是无监督损失的权重,在训练过程中逐渐增加,防止网络训练前期被无意义的目标影响。
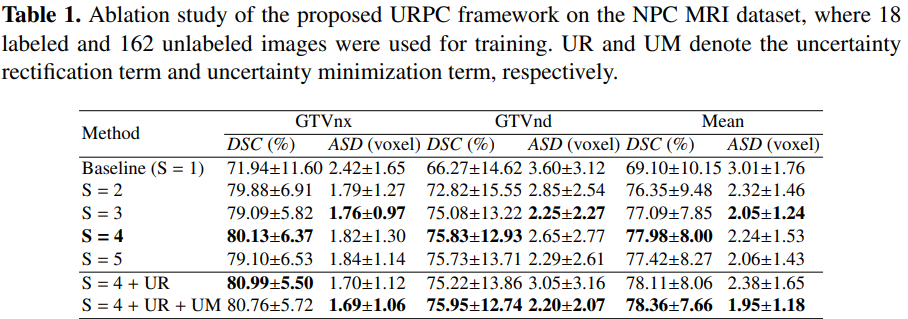
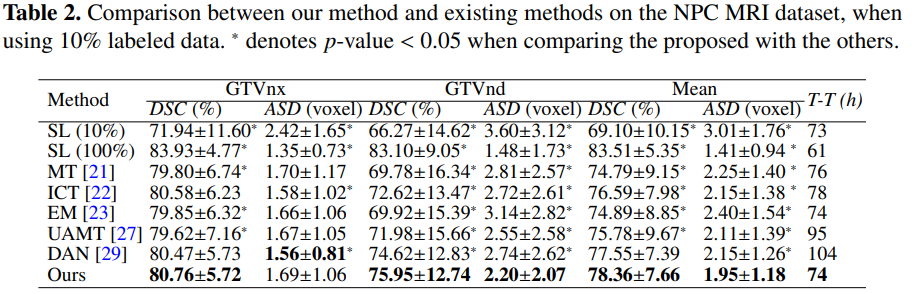
实验:
Uncertainty-Guided Mutual Consistency Learning for Semi-Supervised Medical Image Segmentation, AIIM2022
解读:论文解读《Uncertainty-Guided Mutual Consistency Learning for Semi-Supervised Medical Image Segmentation》_渔歌畅晚的博客-CSDN博客
AIIM 2022 | 半监督医学图像分割-基于不确定性的共一致性学习模型 - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2112.02508
代码:https://github.com/YichiZhang98/UG-MCL
半监督学习着眼于利用少量的带标注的图像数据,并结合获取成本较低的无标注图像数据进行学习,从而达到趋近于使用标注的全监督学习的分割性能。本文提出了一种新的基于不确定性的共一致性学习模型,基于包含两个输出分支生成分割概率图和距离变换图的双任务网络,通过对两个任务分支的输出分别进行集成来进行任务内一致性约束并通过两个任务间的跨任务一致性学习利用图像的几何形状信息。此外,通过利用模型不确定性来对一致性学习进行引导,筛选出分割模型置信度更高的部分进行一致性学习。
基于不确定性的共一致性学习模型:UG-MCL
本文所提出的基于不确定性的共一致性学习模型结构,所使用分割的分割框架网络、包含图像分割任务与距离回归任务这两个任务所对应的输出分支,两个分支的最后一层网络包含着不同的输出层,来分别利用网络编码解码所提取到的特征图来分别生成对应的分割预测图和距离变换图。基于Mean Teacher模型,利用EMA的方式来将训练过程不同时期的Student网络的参数集成至Teacher网络中,并分别对每个任务在Teacher网络和Student网络对应的输出之间进行一致性的计算与学习。
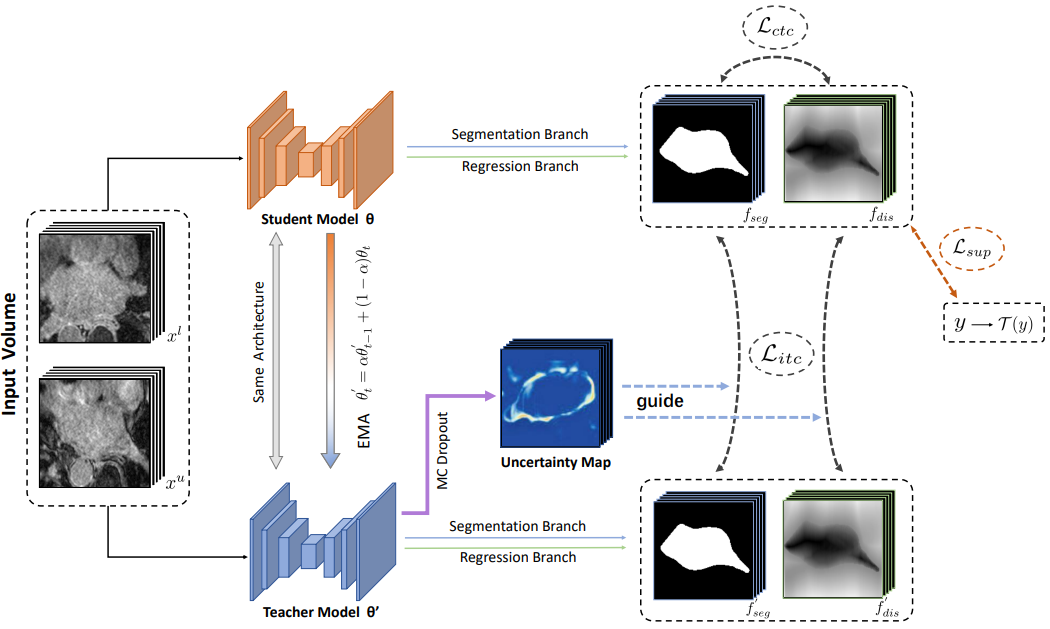
首先,对于有标注的数据,Student模型通过监督学习损失函数来更新参数,实现网络的训练。将监督损失函数添加到两个输出任务的分支来优化网络,通过标注的真值来优化分割任务分支,并通过标注转换的距离变换图真值来优化回归任务的分支。
![]()
半监督学习部分,首先利用自集成模型来构建任务内一致性。网络包含结构相同的Student模型与Teacher模型,其中Student模型通过利用监督损失函数来随着训练逐步进行优化,而Teacher模型则通过EMA来集成训练过程中各个阶段的Student模型。对于Teacher模型与Student模型间一致性的学习,同时考虑了分割任务与回归任务,对两个任务间的输出一致性均进行了约束。并通过MC Dropout来实现对于网络分割结果不确定性的衡量,并通过在半监督学习过程中引入不确定性,来实现对于一致性学习过程的引导。
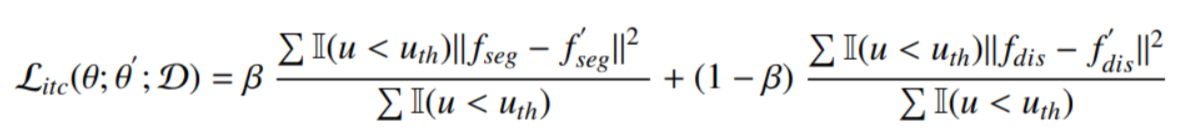
由于不同任务的输出可以引导模型从不同的任务视角学习到分割任务不同的表征,因此通过将不同任务的输出转换为对应的分割掩膜,并通过约束两个分支结果间保持一致,从而实现任务间一致性约束的实现。
![]()
综上,模型通过优化监督学习损失函数,任务内一致性损失函数和任务间一致性损失函数来进行半监督学习。
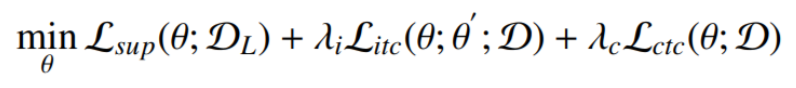
双任务结构:
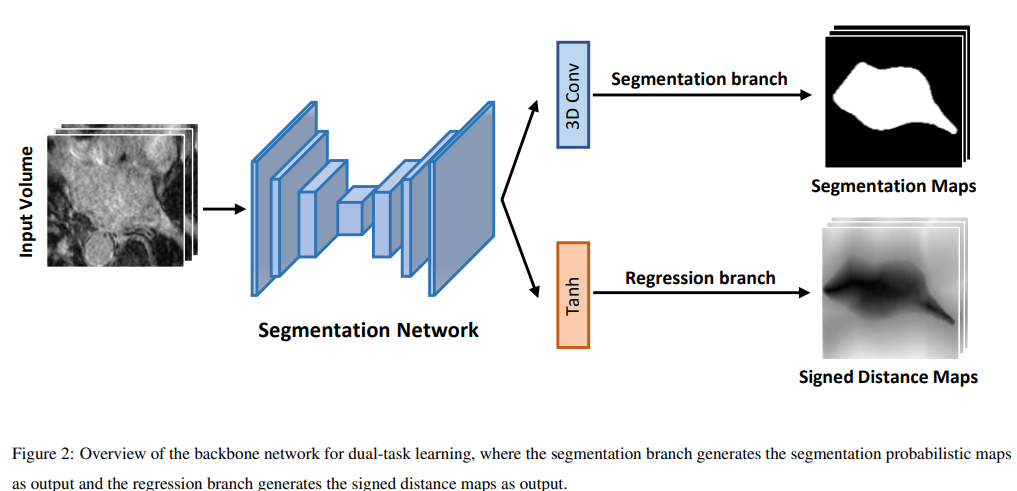
图像分割可看作一个逐像素分类的任务,即将图像中每一个像素分类为目标或者背景,其输出值为该像素对应不同类别的概率值。近年来,一些工作将距离变换图引入分割任务中,从而利用图像中的几何距离信息来提升分割的性能。具体而言,相较于逐像素分类的任务得到的概率图,我们可以将生成距离变换图看作一个回归的任务,所得到的输出中每一个像素的具体值代表着该像素点与目标区域边界之间的距离.
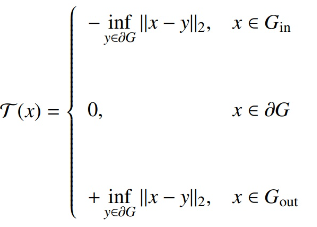
距离变换图对所分割目标物体内部区域的距离取负,而对分割目标物体外部区域的距离取正,其绝对值的大小则代表了该像素点与分割目标边界的像素之间的最近距离。因此,相较于分割输出概率图,距离变换图中的像素值的大小可以表示出该点与物体边界的距离信息,从而表证所分割物体的形状信息。而最终所得的输出的距离变换图可以通过转换成传统的分割任务输出。因此,通过让网络回归生成距离变换图,并将所得输出转化为分割掩模,我们可以在常规的直接生成分割概率图进行分割这一任务之外,将距离变换图作为额外的一个任务来进行图像的分割,从而通过这一任务引入模型对于所分割物体的形状距离信息的学习。
论文算法:

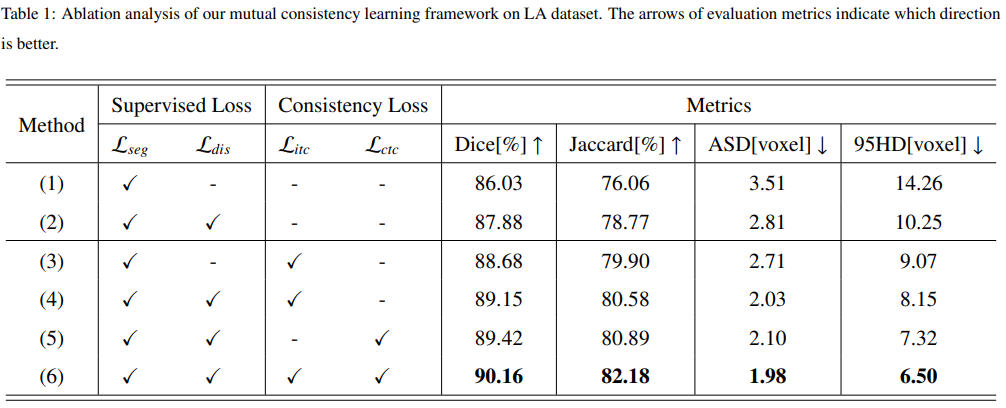
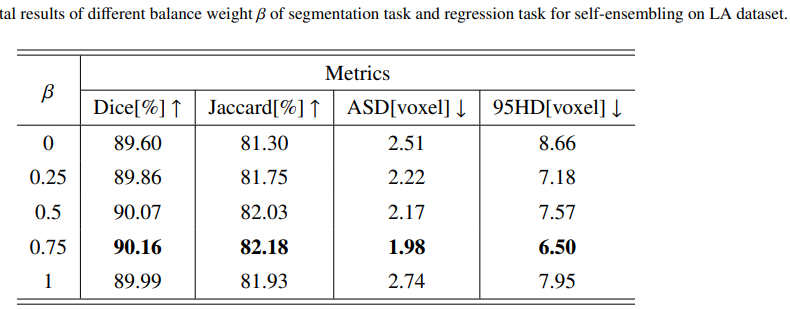
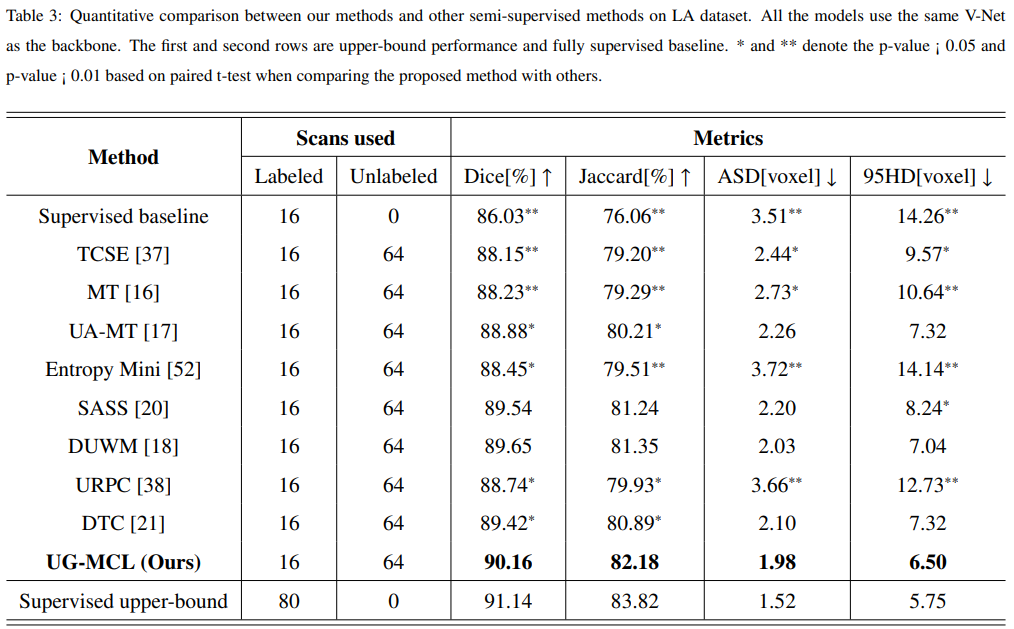
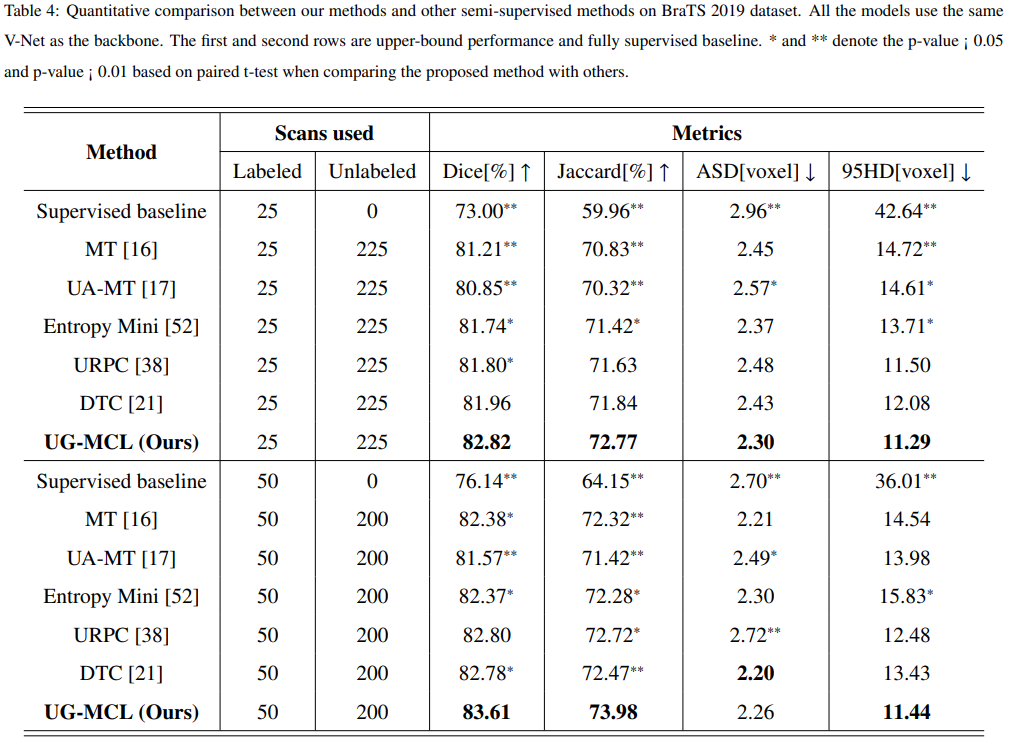
实验:
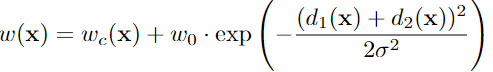


![[转]医学图像分割综述](https://img-blog.csdnimg.cn/20190730135615475.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDc3OTcyNw==,size_16,color_FFFFFF,t_70)