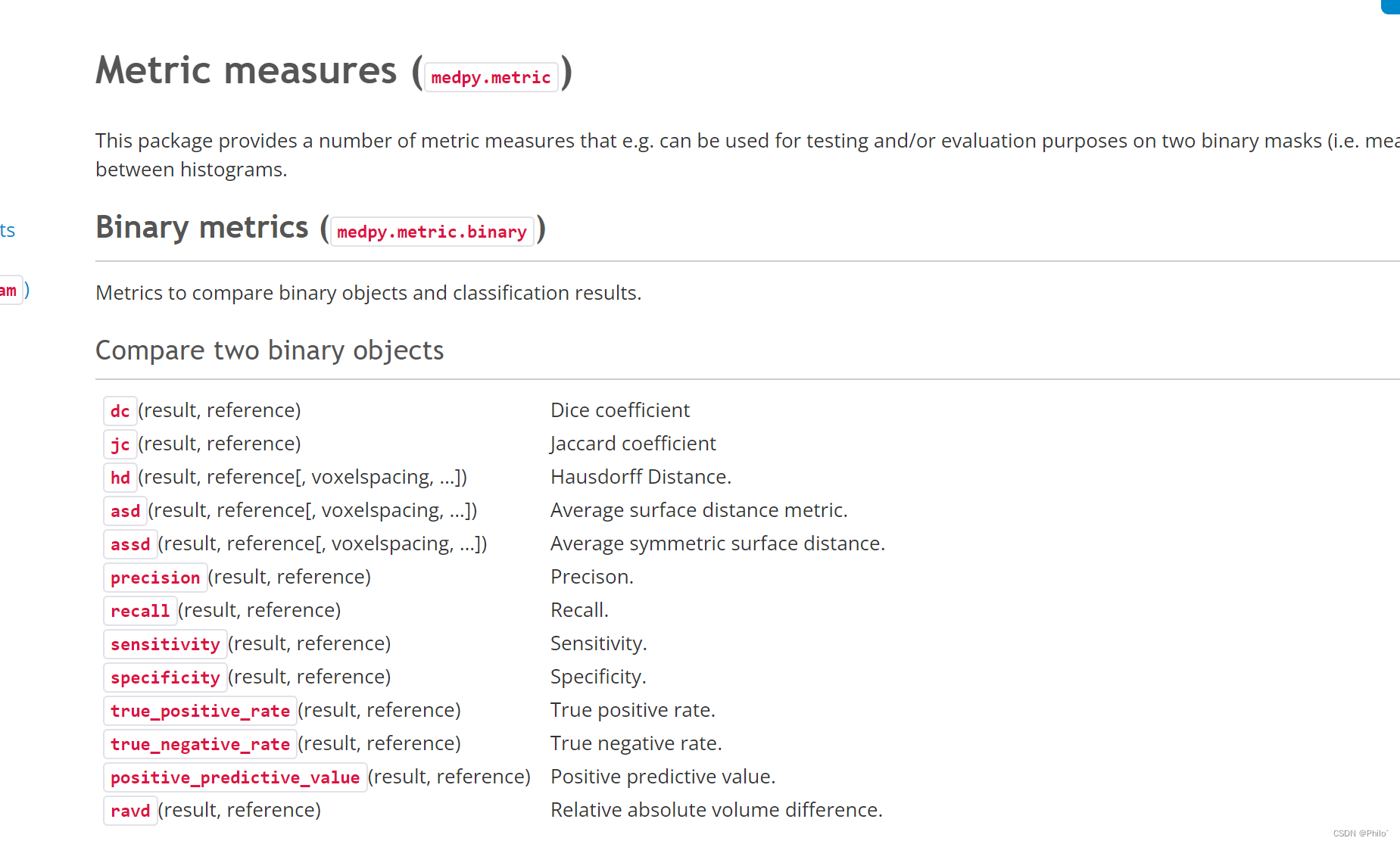
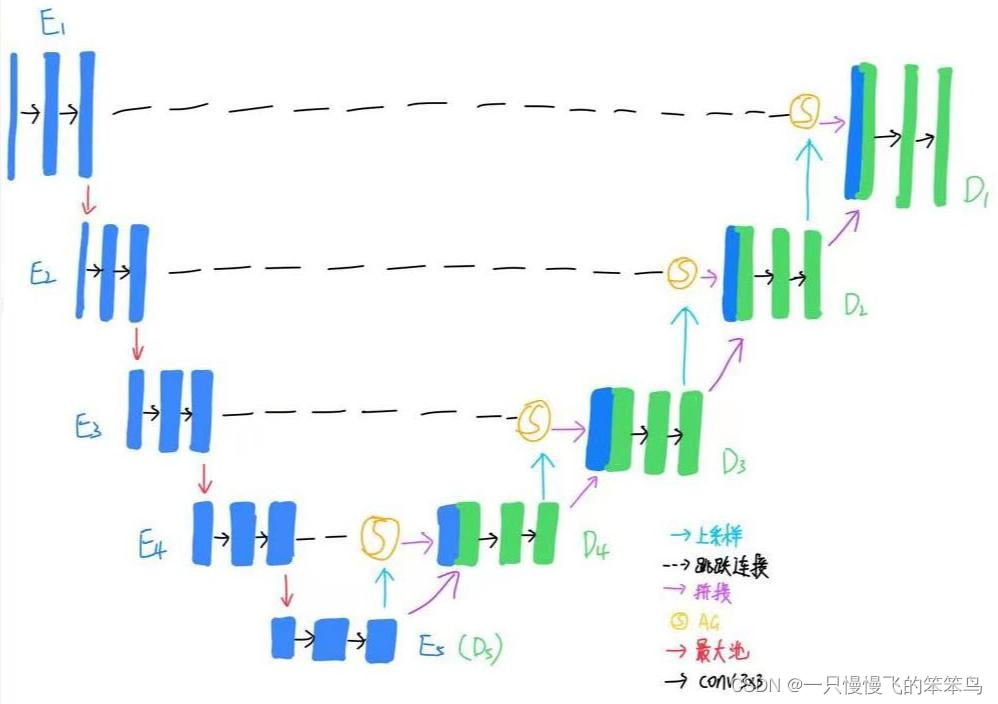
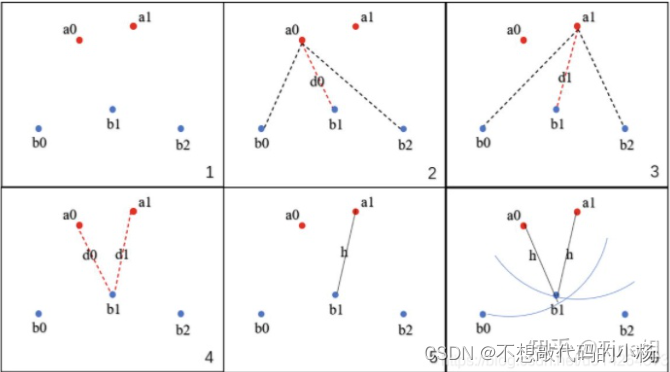
整个实验过程包括:
1、数据集获取:https://zenodo.org/record/3757476
2、数据预处理:从.nii文件中提取包含目标区域的切片,如果不是很清楚医学图像格式的处理,也可以将.nii文件转换成png格式的图片,.nii代码转png图片代码:
import nibabel as nib
import numpy as np
import imageio
import os
def makedir(path):if os.path.exists(path):passelse:os.mkdir(path)def read_niifile(niifile): # 读取niifile文件img = nib.load(niifile) # 下载niifile文件(其实是提取文件)img_fdata = img.get_fdata() # 获取niifile数据return img_fdatadef save_fig(file,savepicdir,name): # 保存为图片fdata = read_niifile(file) # 调用上面的函数,获得数据# (x, y, z) = fdata.shape # 获得数据shape信息:(长,宽,维度-切片数量)# for k in range(z):silce = fdata[:, :, i] # 三个位置表示三个不同角度的切片imageio.imwrite(os.path.join(savepicdir, '{}.png'.format(name)), silce)# 将切片信息保存为png格式
def getName(na):for i in range(0,len(na)):if na[i]=='_':return na[:i]
#传入nii.gz文件所在文件夹
niiGzFolder='/.nii文件夹路径/'
niiGzNames=os.listdir(niiGzFolder)
#存放解压后的分割图片
target='/存放png图片的路径/'
for i in range(0,len(niiGzNames)):niiGzName=niiGzNames[i]name=getName(niiGzName)pred="pred"gt="gt"img="img"if pred in niiGzName:path=target+pred+'/'if gt in niiGzName:path=target+gt+'/'if img in niiGzName:path=target+img+'/'makedir(path)save_fig(niiGzFolder+niiGzName,path,name)print("finish",niiGzName)3、导入自己的数据集,写自己的dataloder,不妨命名为dataset.py,代码如下:
import torch
import cv2
import os
import glob
from torch.utils.data import Dataset
import randomclass Loader(Dataset):def __init__(self, data_path):# print(data_path)images = []image_root = os.path.join(data_path,'images')# print(image_root)for image_name in os.listdir(image_root):image_path = os.path.join(image_root, image_name)images.append(image_path)# 初始化函数,读取所有data_path下的图片self.data_path = data_pathself.imgs_path = imagesdef augment(self, image, flipCode):# 使用cv2.flip进行数据增强,filpCode为1水平翻转,0垂直翻转,-1水平+垂直翻转flip = cv2.flip(image, flipCode)return flipdef __getitem__(self, index):# 根据index读取图片image_path = self.imgs_path[index]# 根据image_path生成label_pathlabel_path = image_path.replace('images', 'labels')# 读取训练图片和标签图片image = cv2.imread(image_path)label = cv2.imread(label_path)# 将数据转为单通道的图片image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)label = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)image = image.reshape(1, image.shape[0], image.shape[1])label = label.reshape(1, label.shape[0], label.shape[1])# 处理标签,将像素值为255的改为1if label.max() > 1:label = label / 255# 随机进行数据增强,为2时不做处理flipCode = random.choice([-1, 0, 1, 2])if flipCode != 2:image = self.augment(image, flipCode)label = self.augment(label, flipCode)return image, labeldef __len__(self):# 返回训练集大小return len(self.imgs_path)if __name__ == "__main__":path='../data/train/'isbi_dataset = Loader(path)print("数据个数:", len(isbi_dataset))train_loader = torch.utils.data.DataLoader(dataset=isbi_dataset,batch_size=2,shuffle=True)for image, label in train_loader:print(image.shape)4、搭建模型,我采用的是U-Net网络,模型包括两个.py文件,unet_model.py和unet_pert.py,训练的时候将这个两个文件放在同一个文件夹,可以叫model
#unet_model.py
import torch.nn.functional as Ffrom .unet_parts import *class UNet(nn.Module):def __init__(self, n_channels, n_classes, bilinear=True):super(UNet, self).__init__()self.n_channels = n_channelsself.n_classes = n_classesself.bilinear = bilinearself.inc = DoubleConv(n_channels, 64)self.down1 = Down(64, 128)self.down2 = Down(128, 256)self.down3 = Down(256, 512)self.down4 = Down(512, 512)self.up1 = Up(1024, 256, bilinear)self.up2 = Up(512, 128, bilinear)self.up3 = Up(256, 64, bilinear)self.up4 = Up(128, 64, bilinear)self.outc = OutConv(64, n_classes)def forward(self, x):x1 = self.inc(x)x2 = self.down1(x1)x3 = self.down2(x2)x4 = self.down3(x3)x5 = self.down4(x4)x = self.up1(x5, x4)x = self.up2(x, x3)x = self.up3(x, x2)x = self.up4(x, x1)logits = self.outc(x)return logitsif __name__ == '__main__':net = UNet(n_channels=3, n_classes=1)print(net)# unet_part
import torch
import torch.nn as nn
import torch.nn.functional as Fclass DoubleConv(nn.Module):"""(convolution => [BN] => ReLU) * 2"""def __init__(self, in_channels, out_channels):super().__init__()self.double_conv = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))def forward(self, x):return self.double_conv(x)class Down(nn.Module):"""Downscaling with maxpool then double conv"""def __init__(self, in_channels, out_channels):super().__init__()self.maxpool_conv = nn.Sequential(nn.MaxPool2d(2),DoubleConv(in_channels, out_channels))def forward(self, x):return self.maxpool_conv(x)class Up(nn.Module):"""Upscaling then double conv"""def __init__(self, in_channels, out_channels, bilinear=True):super().__init__()# if bilinear, use the normal convolutions to reduce the number of channelsif bilinear:self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)else:self.up = nn.ConvTranspose2d(in_channels // 2, in_channels // 2, kernel_size=2, stride=2)self.conv = DoubleConv(in_channels, out_channels)def forward(self, x1, x2):x1 = self.up(x1)# input is CHWdiffY = torch.tensor([x2.size()[2] - x1.size()[2]])diffX = torch.tensor([x2.size()[3] - x1.size()[3]])x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,diffY // 2, diffY - diffY // 2])x = torch.cat([x2, x1], dim=1)return self.conv(x)class OutConv(nn.Module):def __init__(self, in_channels, out_channels):super(OutConv, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)def forward(self, x):return self.conv(x)5、开始训练模型,训练模型我们用train.py文件:
from Unet.model.unet_model import UNet
from Unet.utils.dataset2 import ISBI_Loader
from torch import optim
import torch.nn as nn
import torchdef train_net(net, device, data_path, epochs=40, batch_size=4, lr=0.00001):# 加载训练集isbi_dataset = Loader(data_path)train_loader = torch.utils.data.DataLoader(dataset=isbi_dataset,batch_size=batch_size,shuffle=False)# 定义RMSprop算法optimizer = optim.RMSprop(net.parameters(), lr=lr, weight_decay=1e-8, momentum=0.9)# 定义Loss算法criterion = nn.BCEWithLogitsLoss()# best_loss统计,初始化为正无穷best_loss = float('inf')# 训练epochs次for epoch in range(epochs):# 训练模式net.train()# 按照batch_size开始训练for image, label in train_loader:optimizer.zero_grad()# 将数据拷贝到device中image = image.to(device=device, dtype=torch.float32)label = label.to(device=device, dtype=torch.float32)# 使用网络参数,输出预测结果pred = net(image)# 计算lossloss = criterion(pred, label)print('Loss/train', loss.item())# 保存loss值最小的网络参数if loss < best_loss:best_loss = losstorch.save(net.state_dict(), 'best_model.pth')# 更新参数loss.backward()optimizer.step()if __name__ == "__main__":# 选择设备,有cuda用cuda,没有就用cpudevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 加载网络,图片单通道1,分类为1。net = UNet(n_channels=1, n_classes=3)# 将网络拷贝到deivce中net.to(device=device)# 指定训练集地址,开始训练data_path = "data/train/"train_net(net, device, data_path)6、测试模型test.py文件:
import glob
import numpy as np
import torch
import os
import cv2
from unet_model import UNetif __name__ == "__main__":# 选择设备,有cuda用cuda,没有就用cpudevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 加载网络,图片单通道,分类为1。net = UNet(n_channels=1, n_classes=1)# 将网络拷贝到deivce中net.to(device=device)# 加载模型参数net.load_state_dict(torch.load('best_model.pth', map_location=device))# 测试模式net.eval()# 读取所有图片路径tests_path = glob.glob('data/test/*.png')# 遍历所有图片for test_path in tests_path:# 保存结果地址save_res_path = test_path.split('.')[0] + '_res.png'# 读取图片img = cv2.imread(test_path)# 转为灰度图img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)# 转为batch为1,通道为1,大小为512*512的数组img = img.reshape(1, 1, img.shape[0], img.shape[1])# 转为tensorimg_tensor = torch.from_numpy(img)# 将tensor拷贝到device中,只用cpu就是拷贝到cpu中,用cuda就是拷贝到cuda中。img_tensor = img_tensor.to(device=device, dtype=torch.float32)# 预测pred = net(img_tensor)# 提取结果pred = np.array(pred.data.cpu()[0])[0]# 处理结果pred[pred >= 0.5] = 255pred[pred < 0.5] = 0# 保存图片cv2.imwrite(save_res_path, pred)7、最后的文件目录为,应按要求存放文件,以免出现路径错误、导包错误:

文件目录
8、测试结果:
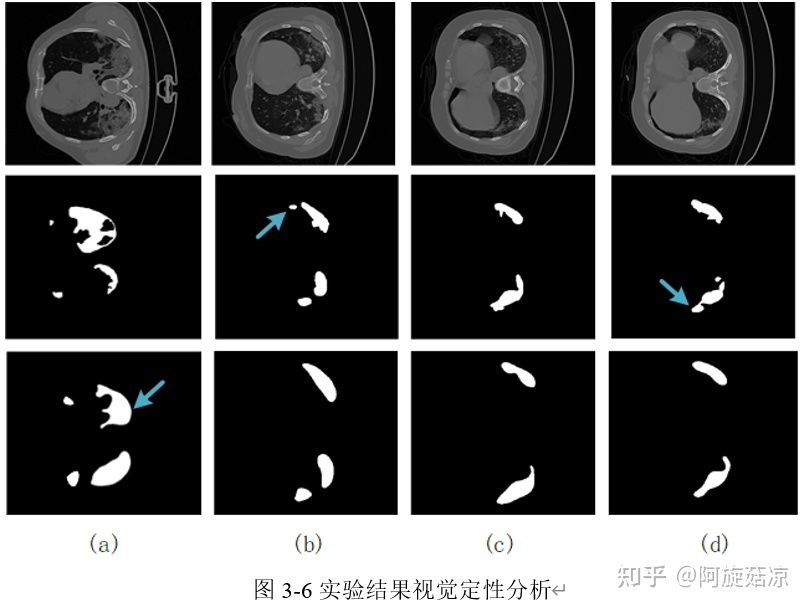
(a)、(b)、(c)、(d)为不同的测试像本,每一列由上到下分别代表原图像、真实标签(GT)和预测分割结果,其中蓝色箭头指向的地方表示预测结果与真实标签的差异
参考链接:Pytorch深度学习实战教程(三):UNet模型训练,深度解析! - 知乎 (zhihu.com)
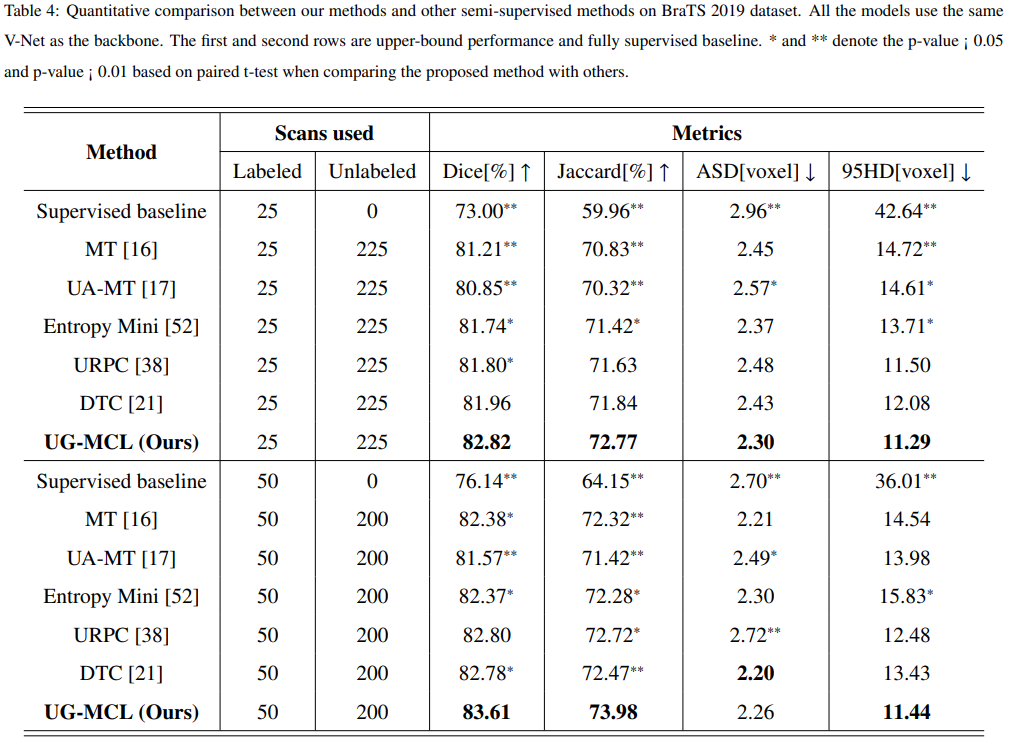
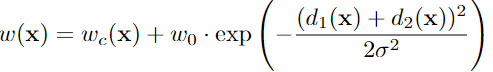


![[转]医学图像分割综述](https://img-blog.csdnimg.cn/20190730135615475.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDc3OTcyNw==,size_16,color_FFFFFF,t_70)