论文:MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation
ConvNeXt网络是一种借鉴Transformer的思想进行了改进实现的全卷积网络,其通过全卷积网络和逆向残差瓶颈单元的设计,可以实现比较大的空间感受野。本文在此基础上提出了新的可伸缩,标准化的网络结构MedNeXt。
MedNeXt是一个全卷积的Encoder-Decoder模式的医学图像分割网络,适用于2d,3d的医学图像分割。模型内部ConvNeXt上采样,ConvNeXt下采样模块可以更好的实现特征的传递。同时论文提出了UpKern方法来通过小卷积核对大卷积核进行初始化来反之少量数据训练时候的模型饱和问题。MedNeXt还是可以自由伸缩的模型,支持多个维度(depth, width, kernel size)的伸缩来适应不同的应用场合。ConvNeXt在效果上也是略优于nnUNet。
主要贡献:
(1)利用ConvNeXt这种全卷积网络的思想,设计了一个纯卷积模块(purely of ConvNeXt blocks)组成的网络结构MedNeXt。
(2)有别于正常的上采样,下采样模块,论文提出了逆向残差瓶颈单元(Residual Inverted Bottlenecks),使用该模块来实现上下采样操作。该模块有助于保存丰富的特征同时提高了梯度的传递效果。
(3)提出了一个简单高效的不同大小kernel的参数初始化方法UpKern,保证模型具有较好的初始化。
(4)提出了模型伸缩的方法(Compound Scaling),保证了模型在宽度width (channels),感受野receptive field (kernel size) , 深度depth (number of layers)等方向的伸缩。
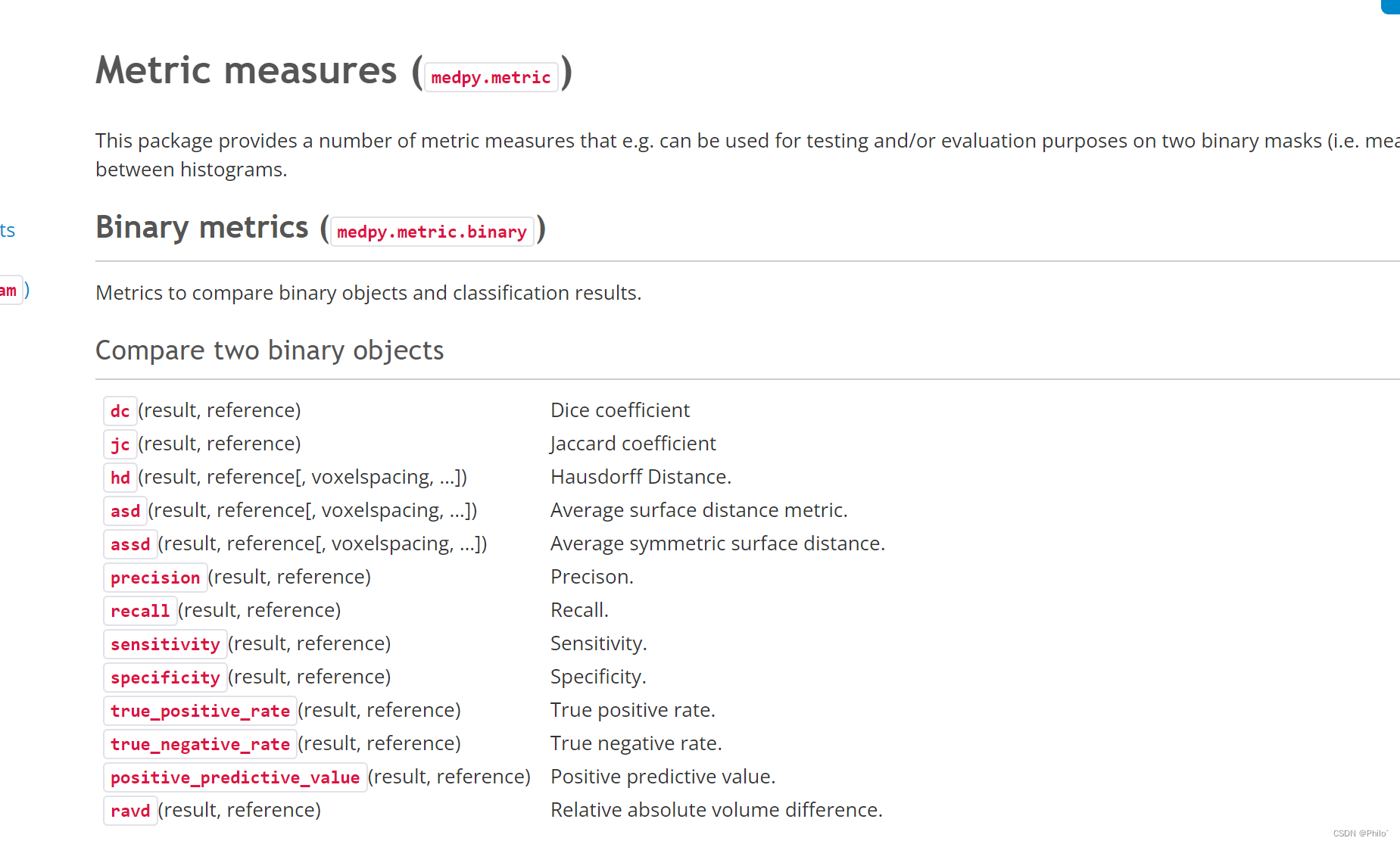
网络结构:
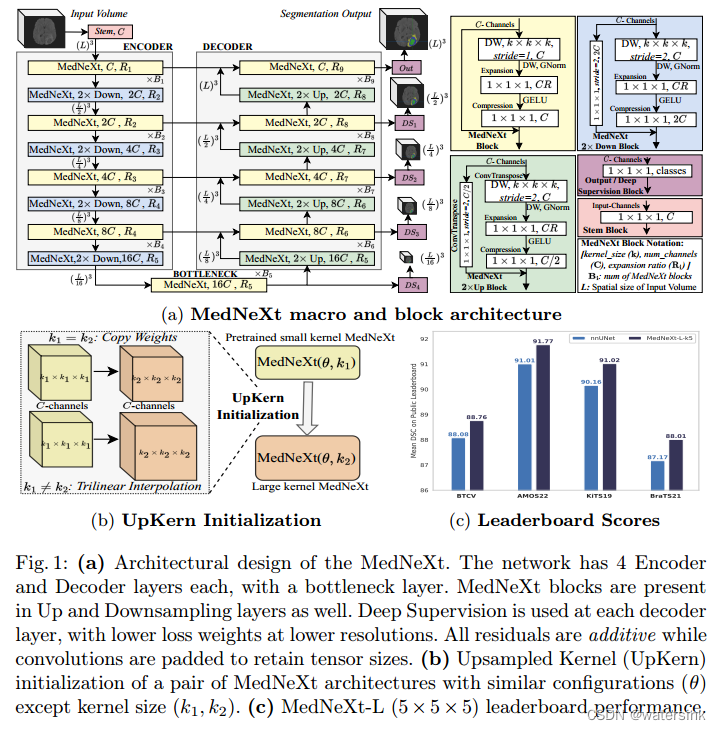
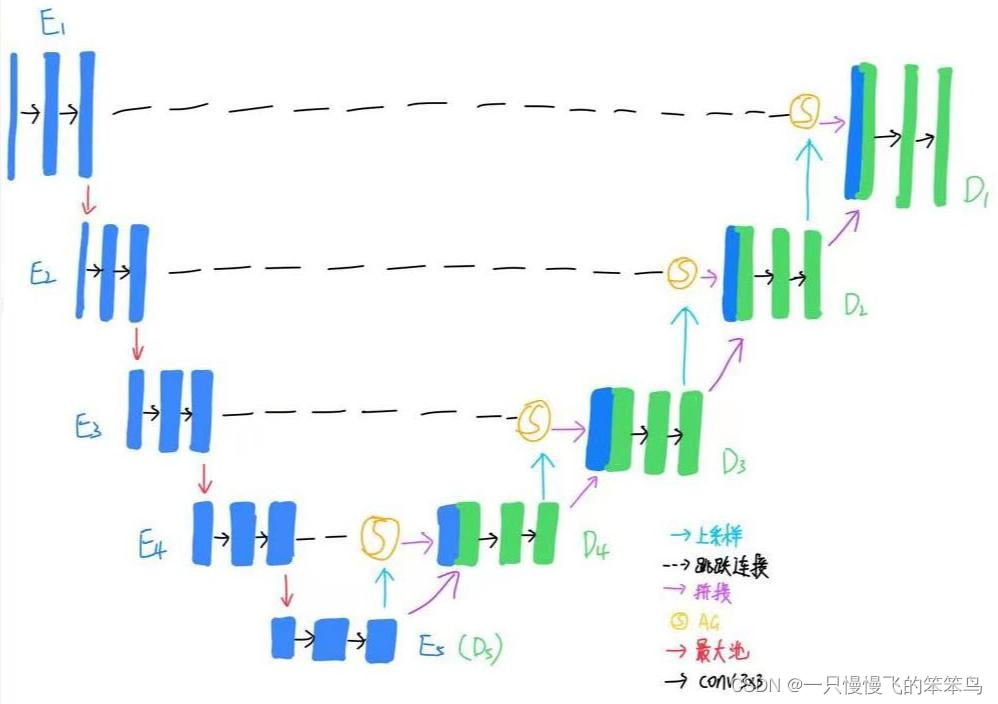
网络的整体设计还是全卷积编码器-解码器这种U型结构。如果是3d分割输入为128*128*128,如果是2d分割输入为512*512。
其中R代表通道的扩展率,C表示通道数,B表示block的堆叠次数,L表示输入的分辨率大小。
Steam block(粉色):
由于MedNeXt网络同时支持2d,3d的分割任务。由于是全卷积的设计思想,所以不同输入图像的宽,高不会产生影响,但是不同的通道数却是会对模型产生影响。如果做到训练一个预训练模型,同时兼任2d,3d任务呢?这就是steam模块的作用。该模块通过一个1*1*1的卷积实现,可以实现将不同通道数的输入都压缩在同样的通道数目上,这样就保证了模型参数的可复用。
MedNeXt block(黄色):
该模块整体是一个逆向的残差模块,模块先经过一个stride=1的深度可分离卷积(DW),然后做一个GroupNorm操作,这里有别于Swin-Transformers中的LayerNorm操作。这样做的目的是为了保证小batch训练的稳定性。然后再经过一个1*1*1卷积,对通道数进行R倍增加,并基于GELU激活,最后再经过一个1*1*1,对通道数进行压缩,最终保证输入的通道数等于输出的通道数,输入的分辨率等于输出的分辨率。最后将该分支的输出和shortcut直连的输出进行汇合,得到最终的模块输出。
MedNeXt 2x Down block(蓝色):
该模块与MedNeXt block的区别有2点。第1个区别是输入部分换为stride=2的深度可分离卷积(DW),实现了网络的下采样操作。第2个区别是shortcut分支加入了1*1*1卷积保证输出的通道数2倍增加,以及最后一个1*1*1卷积实现了通道数的2倍增加。最终输入特征通过MedNeXt 2x Up block可以实现2倍的下采样,通道2倍的升维。
MedNeXt 2x Up block(绿色):
该模块与MedNeXt block的区别有2点。第1个区别是输入部分换为stride=2的深度可分离反卷积(DW ConvTranspose),实现了网络的上采样操作。第2个区别是shortcut分支加入了1*1*1卷积保证输出的通道数2倍减少,以及最后一个1*1*1卷积实现了通道数的2倍减少。最终输入特征通过MedNeXt 2x Down block可以实现2倍的上采样,通道2倍的降维。
Output/Deep Supervision block(紫色):
该模块通过1*1*1卷积实现将特征缩放到classes维度。
UpKern:
Swin Transformer V2中大的attention-window的初始化是使用小的attention-window进行初始化的。偏置参数 B大小为(2M-1)×(2M-1),M表示attention-window中的patch个数,不同大小窗口的B是不一样的,这里也是通过空间插值(spatially interpolating)的方法进行实现的。本文的UpKern思想就来源于此。对于一样大小的卷积核使用直接复制权值的方法进行初始化,对于比较大的卷积核,通过对小的卷积核进行三线插值得到大的卷积核。通过这样的初始化方法可以避免模型的性能饱和。
论文给出了Pytorch版本的实现,
import torch . functional as F
def upkern_init_load_weights ( network , pretrained_net ):pretrn_dct = pretrained_net . state_dict ()model_dct = network . state_dict ()for k in model_dct . keys ():# Only common keys and core algorithm in Demo codeif k in model_dct . keys () and k in pretrn_dct . keys ():inc1 , outc1 , * spt_dims1 = model_dct [k]. shapeinc2 , outc2 , * spt_dims2 = pretrn_dct [k]. shapeif spt_dims1 == spt_dims2 : # standard initmodel_dct [k] = pretrn_dct [k]else : # Upsampled kernel initmodel_dct [k] = F. interpolate (pretrn_dct [k],size = spt_dims1 ,mode =’trilinear ’)network . load_state_dict ( model_dct )return network
Compound Scaling of Depth, Width and Receptive Field:
本文的模型通过调节block count (B)来调节深度(depth),调节expansion ratio (R) 来调节宽度(width),调节kernel size (k) 来调节感受野(receptive field size)。最终实现模型的可伸缩扩展。最终提出了S,B,M,L四种不同大小的网络来适应不同应用场景。

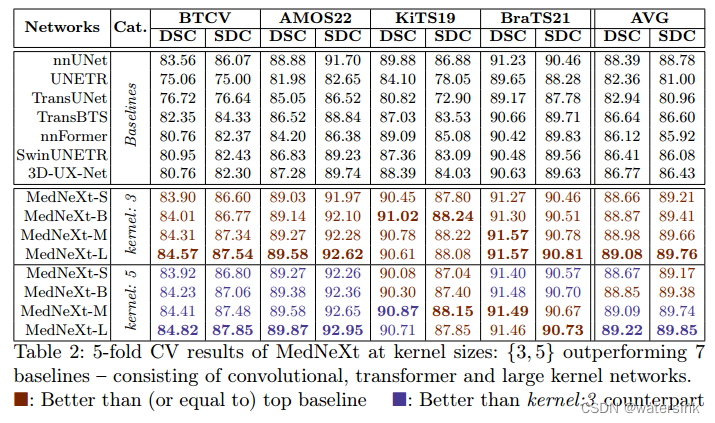
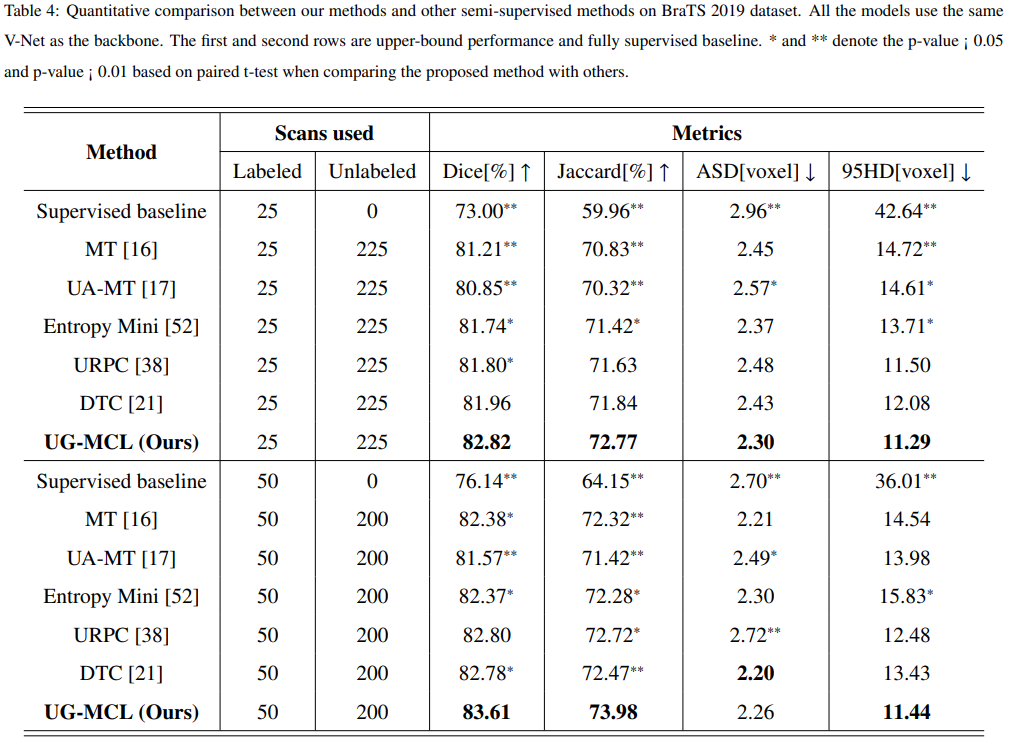
实验结果:
总结:
本文提出了一种具备高度可扩展性的类ConvNeXt的 3D 分割架构,其在有限的医学图像数据集上优于其它 7 个顶流方法,当中就包含了非常强的nnUNet。MedNeXt设计作为标准卷积块的有效替代,完全可作为医学图像分割领域的新网络架构标杆之作!
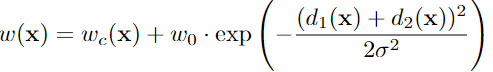


![[转]医学图像分割综述](https://img-blog.csdnimg.cn/20190730135615475.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDc3OTcyNw==,size_16,color_FFFFFF,t_70)