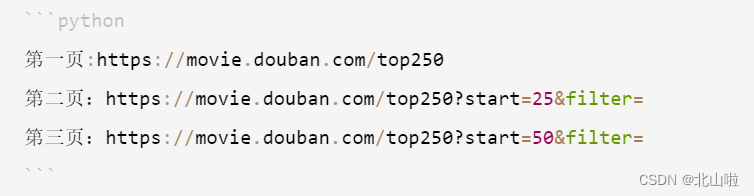
分析


通过上面两张图片可以发现
第一页url:https://movie.douban.com/top250?start=0&filter=
第二页url:https://movie.douban.com/top250?start=25&filter=
由此类推
第n页url
https://movie.douban.com/top250?start=n-1然后×25&filter=
代码
import requests, csv # 使用requests请求,csv保存数据
from lxml import etree # 使用xpath解析
import multiprocessing # 使用多进程加快爬虫速度class DoubanSpider:# 设置请求头def __init__(self):self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}# 定义一个发送请求并返回响应的实例方法,方便调用def get_response(self, url):response = requests.get(url, headers=self.headers)response.encoding = 'utf-8'return response# 提取数据def get_data(self, url):response = self.get_response(url)html = etree.HTML(response.text)hrefs = html.xpath('//div[@class="hd"]/a/@href') # 电影url链接movies_name = html.xpath('//div[@class="hd"]/a/span[1]/text()') # 电影名称score = html.xpath('//div[@class="bd"]//span[2]/text()') # 电影评分for movie_name, movie_url, movie_score in zip(movies_name, hrefs, score):print('正在保存' + movie_name)self.save_local(movie_name, movie_url, movie_score)# 将数据保存到本地def save_local(self, movie_name, movie_url, movie_score):with open(r'C:\Users\thomas\Desktop' + '\\豆瓣排名.csv', 'a', encoding='utf-8') as f:w = csv.writer(f)w.writerow([movie_name, movie_url, movie_score]) # 每一条数据if __name__ == '__main__':pool = multiprocessing.Pool(30) # 30个进程url = "https://movie.douban.com/top250?start={}&filter="spider = DoubanSpider()pool.map(spider.get_data, [url.format(i * 25) for i in range(100)]) # 异步抓取99页
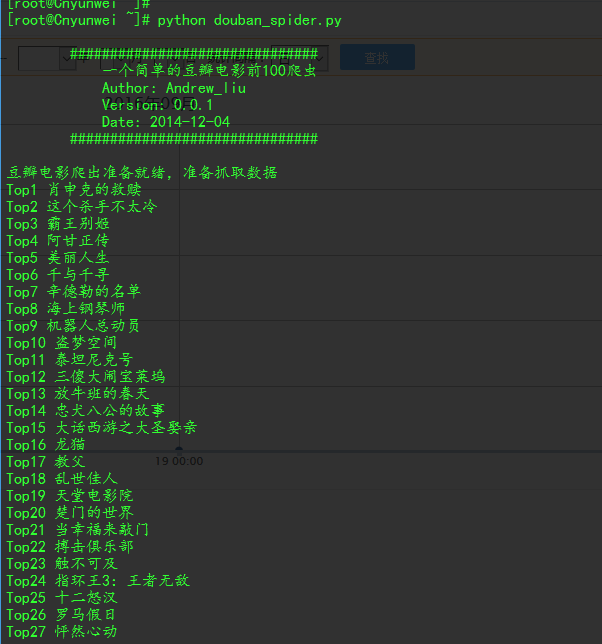
数据展示