摘要:对于程序员或开发人员来说,拥有编程能力使得他们构建一个网页数据爬取程序,非常的容易并且有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定网页获取特定内容。
网页数据爬取是指从网站上提取特定内容,而不需要请求网站的API接口获取内容。“网页数据” 作为网站用户体验的一部分,比如网页上的文字,图像,声音,视频和动画等,都算是网页数据。
对于程序员或开发人员来说,拥有编程能力使得他们构建一个网页数据爬取程序,非常的容易并且有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定网页获取特定内容。以下是一些使用八爪鱼采集器抓取网页数据的几种解决方案:
1、从动态网页中提取内容
网页可以是静态的也可以是动态的。通常情况下,您想要提取的网页内容会随着访问网站的时间而改变。通常,这个网站是一个动态网站,它使用AJAX技术或其他技术来使网页内容能够及时更新。AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
表现特征为点击网页中某个选项时,大部分网站的网址不会改变;网页不是完全加载,只是局部进行了数据加载,有所变化。这个时候你可以在八爪鱼的元素“高级选项”的“Ajax加载”中可以设置,就能抓取Ajax加载的网页数据了。
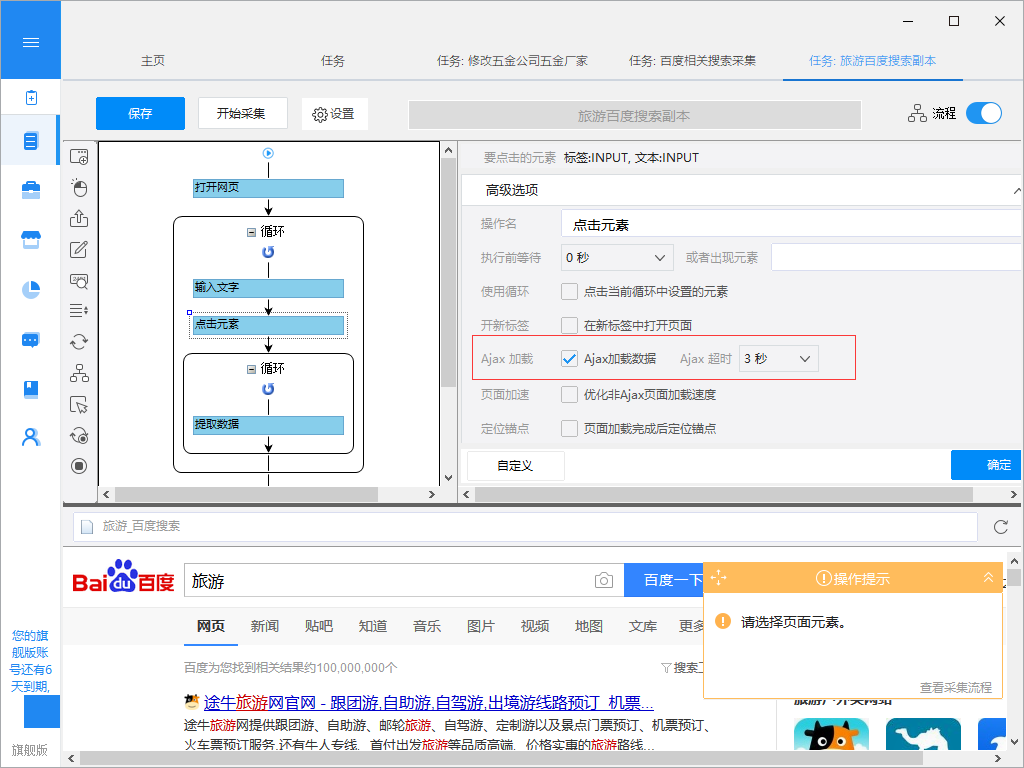
2、从网页中抓取隐藏的内容
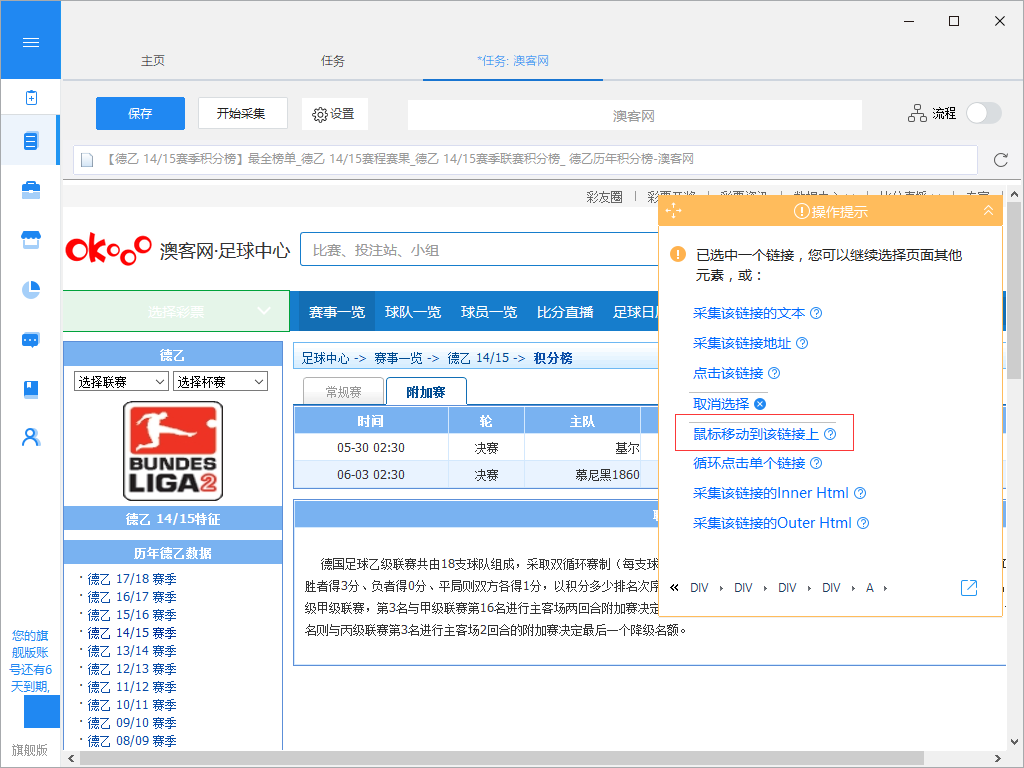
你有没有想过从网站上获取特定的数据,但是当你触发链接或鼠标悬停在某处时,内容会出现?例如,下图中的网站需要鼠标移动到选择彩票上才能显示出分类,这对这种可以设置“鼠标移动到该链接上”的功能,就能抓取网页中隐藏的内容了。
3、从无限滚动的网页中提取内容
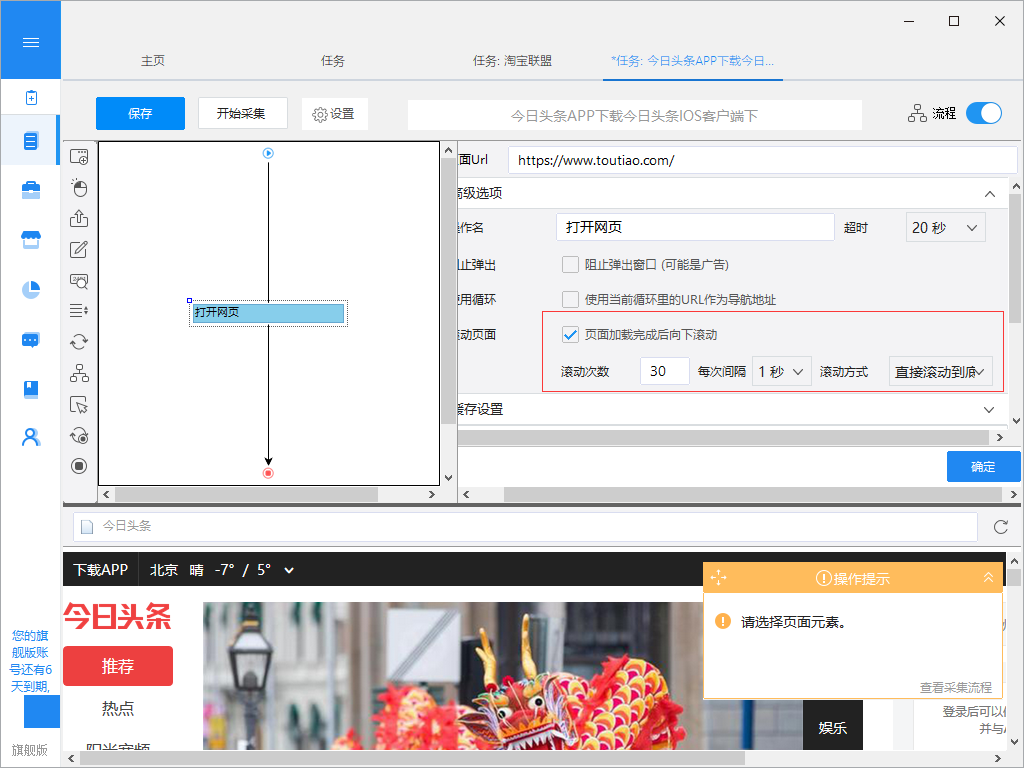
在滚动到网页底部之后,有些网站只会出现一部分你要提取的数据。例如今日头条首页,您需要不停地滚动到网页的底部以此加载更多文章内容,无限滚动的网站通常会使用AJAX或JavaScript来从网站请求额外的内容。在这种情况下,您可以设置AJAX超时设置并选择滚动方法和滚动时间以从网页中提取内容。
4、从网页中爬取所有链接
一个普通的网站至少会包含一个超级链接,如果你想从一个网页中提取所有的链接,你可以用八爪鱼来获取网页上发布的所有超链接。
5、从网页中爬取所有文本
有时您需要提取HTML文档中的所有文本,即放置在HTML标记(如<DIV>标记或<SPAN>标记)之间的内容。八爪鱼使您能够提取网页源代码中的所有或特定文本。
6、从网页中爬取所有图像
有些朋友有采集网页图片的需求。八爪鱼可以将网页中图片的URL采集,再通过下载使用八爪鱼专用的图片批量下载工具,就能将我们采集到的图片URL中的图片下载并保存到本地电脑中。