文章目录
- 一.摘要
- 二.背景介绍
- 三.GAT
- 四.总结
- 五.附录
一.摘要
我们提出了图注意网络(GAT),一种在图结构数据上运行的新型神经网络架构,利用掩蔽的自我注意层来解决基于图形卷积或其近似的先前方法的缺点。通过堆叠节点能够参与其邻域特征的层,我们能够(隐式)为邻域中的不同节点指定不同的权重,而不需要任何类型的昂贵的矩阵运算(例如求逆)或依赖于对图的了解结构前期。通过这种方式,我们同时解决了基于谱的图神经网络的几个关键挑战,并使我们的模型很容易适用于归纳和转导问题。我们的 GAT 模型在四个已建立的转导和归纳图基准测试中取得或匹配了最先进的结果:Cora、Citeseer 和 Pubmed 引文网络数据集,以及蛋白质相互作用数据集。
二.背景介绍
卷积神经网络 (CNN) 已成功应用于解决图像分类、语义分割或机器翻译等问题。 这些问题的底层数据表示具有类似网格结构。 这些结构通过将它们应用于所有输入位置,有效地重用具有可学习参数的本地滤波器。
然而,许多有趣的任务涉及的数据不能以网格状结构表示,而是位于不规则域中。 3D 网格、社交网络、电信网络、生物网络或大脑连接组就是这种情况。 这样的数据通常可以用图的形式来表示。
文献中有几次尝试扩展神经网络以处理任意结构的图。:早期的工作使用递归神经网络来处理在图域中表示为有向无环图的数据。 2005年Gori和 Scarselli 等人提出的图神经网络 (GNN)作为递归神经网络的推广,可以直接处理例如循环图、有向图和无向图等更通用的图类。 GNN由一个迭代过程组成,该过程传播节点状态直到达到平衡; 然后紧跟一个神经网络,根据每个节点的状态为每个节点生成一个输出。 这个想法后来又被李等人采纳和改进,在传播步骤中使用门控循环单元。
然而,将卷积推广到图域受到越来越多的关注,这个方向的进展通常分为光谱方法和非光谱方法。
一方面,谱方法与图的谱表示一起工作,并已成功应用于上下文中的节点分类。在布鲁纳等人的工作中,卷积运算是通过计算图拉普拉斯算子的特征分解在傅里叶域中定义的,从而导致潜在的密集计算和非空间局部化滤波器。这些问题在随后的工作中得到解决,赫纳夫等人引入了具有平滑系数的光谱滤波器的参数化,以使它们在空间上局部化。再后来,Defferrard 等人提出通过图拉普拉斯算子的切比雪夫展开来近似过滤器,消除了计算拉普拉斯算子的特征向量并产生空间局部化过滤器的需要。最后,Kipf和Welling等人通过限制过滤器在每个节点周围的 1 步邻域内操作来简化之前的方法。然而,在所有上述谱方法中,学习滤波器依赖于取决于图结构的拉普拉斯特征基。因此,在特定结构上训练的模型不能直接应用于具有不同结构的图。
另一方面,我们有非谱方法,它直接在图上定义卷积,对空间近邻组进行操作。这些方法的挑战之一是定义一个与不同大小的邻域一起工作并保持 CNN 的权重共享属性的算子。在某些情况下,这需要为每个节点度学习一个特定的权重矩阵,使用转换矩阵的幂来定义邻域,同时学习每个输入通道和邻域度的权重,或提取和归一化包含固定数量节点的邻域。蒙蒂等人2016 年提出了混合模型 CNN(MoNet),这是一种空间方法,可将 CNN 架构统一推广到图。最近,汉密尔顿等人介绍了GraphSAGE,这是一种以归纳方式计算节点表示的方法。该技术通过对每个节点的固定大小邻域进行采样,然后对其执行特定的聚合器(例如所有采样邻居的特征向量的平均值,或通过循环神经网络馈送它们的结果)来操作。这种方法在多个大规模归纳基准测试中取得了令人印象深刻的性能。
在许多基于序列的任务中,注意力机制几乎已成为事实上的标准。 注意力机制的好处之一是它们允许处理可变大小的输入,专注于输入中最相关的部分以做出决策。 当使用注意力机制来计算单个序列的表示时,它通常被称为自注意力或内部注意力。 与循环神经网络 (RNN) 或卷积一起,自注意力已被证明对机器阅读和学习句子表示等任务很有用。 然而,瓦斯瓦尼等人表明,self-attention 不仅可以改进基于 RNN 或卷积的方法,而且足以构建一个强大的模型,在机器翻译任务上获得最先进的性能。
受最近这项工作的启发,我们引入了一种基于注意力的架构来执行图结构数据的节点分类。这个想法是通过关注其邻居,遵循自注意力策略来计算图中每个节点的隐藏表示。注意力架构有几个有趣的特性:(1)操作是高效的,因为它可以跨节点邻居对并行化; (2) 通过给邻居指定任意权重,可以将其应用于具有不同度数的图节点; (3) 该模型直接适用于归纳学习问题,包括模型必须泛化到完全看不见的图的任务。我们在四个具有挑战性的基准上验证了所提出的方法:Cora、Citeseer 和 Pubmed 引文网络以及归纳蛋白质-蛋白质相互作用数据集,实现或匹配最先进的结果,这些结果突出了基于注意力的模型在处理时的潜力带有任意结构的图。
值得注意的是,与 Kipf和 Atwood等人一样,我们的工作也可以重新表述为MoNet的一个特定实例。此外,我们跨边缘共享神经网络计算的方法让人想起关系网络和 VAIN 的公式,其中对象或代理之间的关系是成对聚合的,通过采用一种共享机制。同样,我们提出的注意力模型可以与 Duan 等人的工作联系起来,它使用邻域注意操作来计算环境中不同对象之间的注意系数。其他相关方法包括局部线性嵌入 (LLE) 和记忆网络:LLE 在每个数据点周围选择固定数量的邻居,并为每个邻居学习一个权重系数,以将每个点重构为其邻居的加权和,第二个优化步骤提取点的特征嵌入;记忆网络也与我们的工作有一些联系,特别是如果我们将节点的邻域解释为记忆,它用于通过关注其值来计算节点特征,然后通过将新特征存储在相同的位置。
三.GAT
在本节中,我们将介绍用于构建任意图注意力网络的构建块层(通过堆叠该层),并直接概述其与神经图处理领域的先前工作相比的理论和实践优势和局限性。
我们将从描述单个图形注意层开始,作为我们实验中使用的所有 GAT 架构中使用的唯一层。 我们使用的特殊注意力设置与 Bahdanau 等人的工作密切相关,但该框架与注意力机制的特定选择无关。
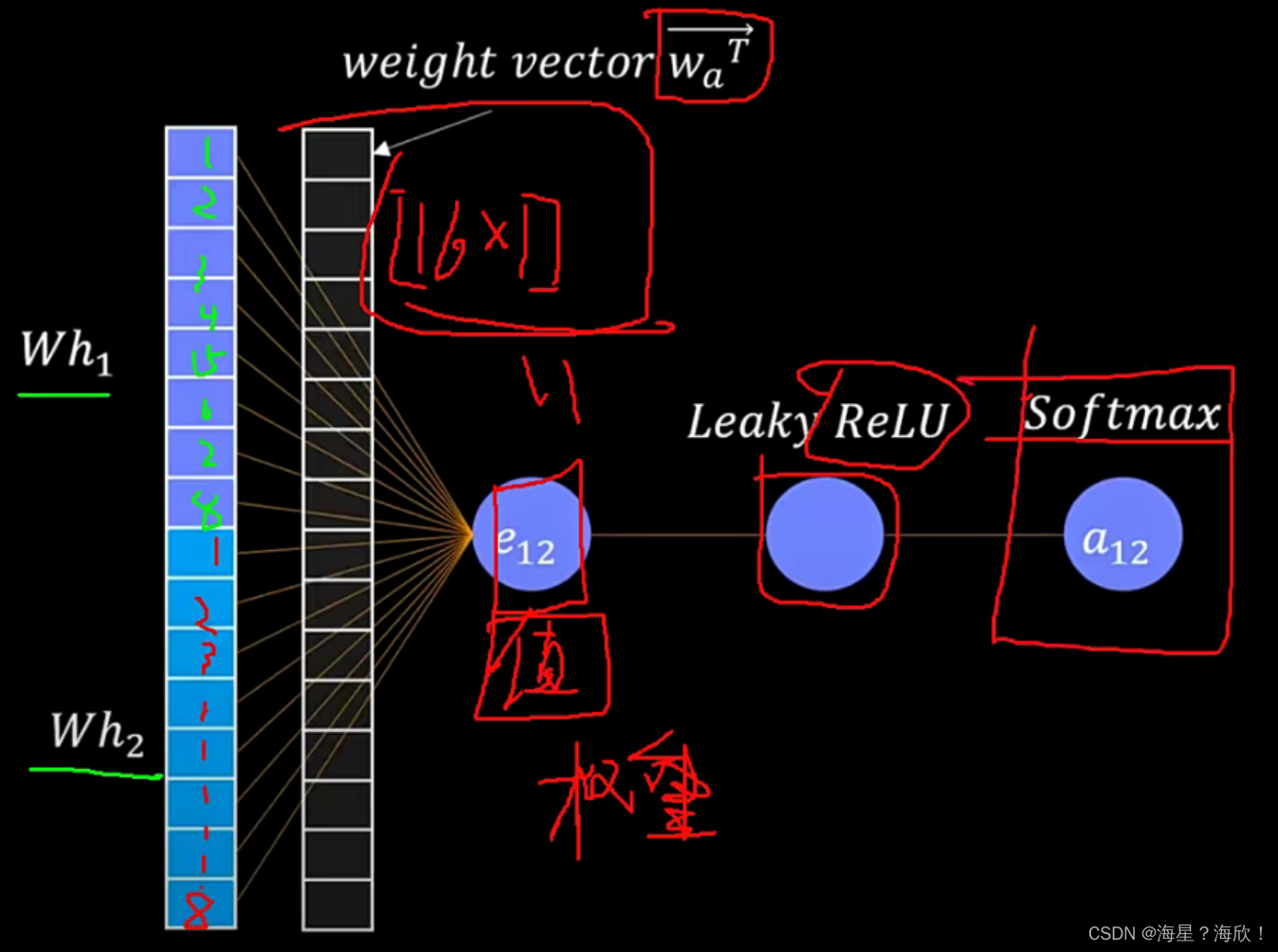
我们层的输入是一组节点特征,$h = {\overrightarrow{h_1},\overrightarrow{h_2}, . . . ,\overrightarrow{h_N} }, \overrightarrow{h_i} ∈ R^F ,其中 N 是节点数, F 是每个节点中的特征数。该层产生一组新的节点特征(可能具有不同的基数 F ′ ), ,其中 N 是节点数,F 是每个节点中的特征数。 该层产生一组新的节点特征(可能具有不同的基数 F'), ,其中N是节点数,F是每个节点中的特征数。该层产生一组新的节点特征(可能具有不同的基数F′),h’ = {\overrightarrow{h’_1},\overrightarrow{h’_2}, . . . ,\overrightarrow{h’_N} },\overrightarrow{h’_i} ∈ R^{F’} ,作为其输出。为了获得足够的表达能力将输入特征转化为更高级的特征,至少需要一个可学习的线性变换。为此,作为初始步骤,将由权重矩阵 ,作为其输出。为了获得足够的表达能力将输入特征转化为更高级的特征,至少需要一个可学习的线性变换。 为此,作为初始步骤,将由权重矩阵 ,作为其输出。为了获得足够的表达能力将输入特征转化为更高级的特征,至少需要一个可学习的线性变换。为此,作为初始步骤,将由权重矩阵 W ∈ R^{F’×F} 参数化的共享线性变换应用于每个节点。然后我们在节点上执行自我注意——共享注意机制 a : 参数化的共享线性变换应用于每个节点。 然后我们在节点上执行自我注意——共享注意机制 a : 参数化的共享线性变换应用于每个节点。然后我们在节点上执行自我注意——共享注意机制a: R^{F’}× R^{F’} → R $计算注意系数:

表示节点 j 的特征对节点 i 的重要性。 在其最一般的表述中,该模型允许每个节点参与每个其他节点,删除所有结构信息。 我们通过执行 masked attention 将图结构注入到机制中——我们只计算节点 j ∈ Ni 的 eij,其中 Ni 是图中节点 i 的某个邻域。 在我们所有的实验中,这些将恰好是 i(包括 i)的一阶邻居。 为了使系数在不同节点之间易于比较,我们使用 softmax 函数在 j 的所有选择中对它们进行归一化:

在我们的实验中,注意力机制 a 是一个单层前馈神经网络,由权重向量$ \overrightarrow a ∈ R^{2F’} $参数化,并应用 LeakyReLU 非线性(负输入斜率 α = 0.2)。 完全展开后,注意力机制计算的系数(如图 1(左)所示)可以表示为:


一旦获得,归一化的注意力系数用于计算与其对应的特征的线性组合,作为每个节点的最终输出特征(在可能应用非线性后,σ):

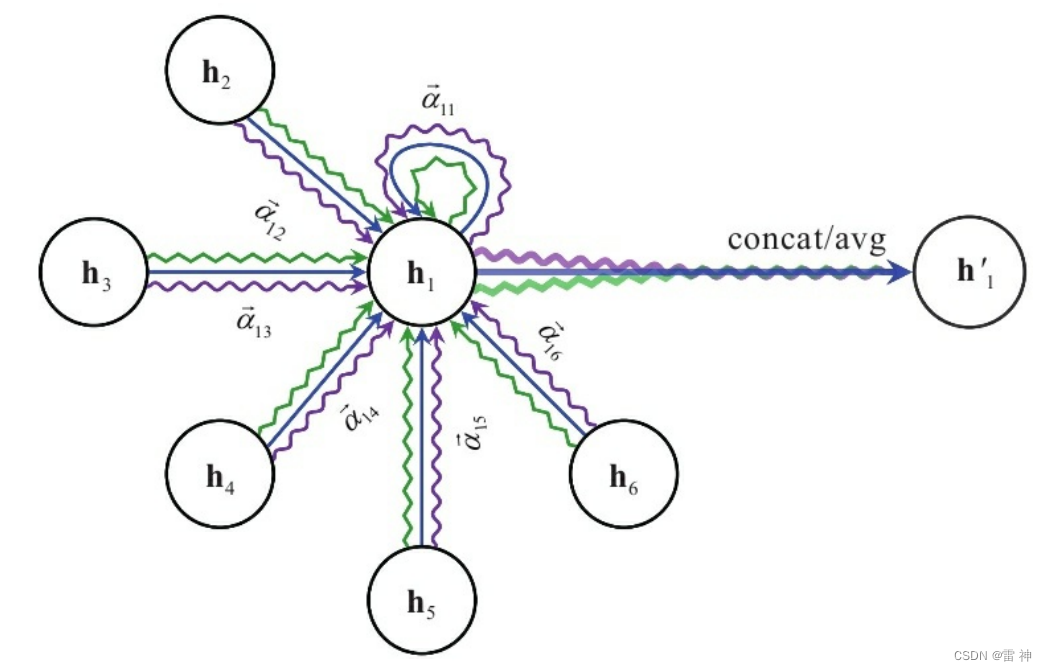
为了稳定自注意力的学习过程,我们发现扩展我们的机制以使用类似于 Vaswani 等人的多头注意力是有益的,具体来说,K 个独立的注意力机制执行方程 4 的转换,然后将它们的特征连接起来,得到以下输出特征表示:

特别是,如果我们在网络的最终(预测)层执行多头注意力,则连接不再有意义——相反,我们采用平均,并延迟应用最终的非线性(通常是用于分类问题的 softmax 或逻辑 sigmoid)直到 然后:

多头图注意力层的聚合过程如图 1(右)所示。
四.总结
本文提出了图注意力网络 (GAT),一种新颖的卷积式神经网络,它在图结构数据上运行,利用了掩码自注意力层。在这些网络中使用的图注意力层在计算上是高效的(不需要昂贵的矩阵运算,并且可以在图中的所有节点上并行化),允许在处理不同大小的邻域时(隐式)为邻域内的不同节点分配不同的重要性,并且不依赖于预先了解整个图结构,从而解决了以前基于谱的方法的许多理论问题。我们利用注意力的模型已经在四个成熟的节点分类基准中成功实现或匹配了最先进的性能,包括转换和归纳(尤其是用于测试的完全看不见的图表)。
五.附录
论文链接:https://arxiv.org/pdf/1710.10903.pdf
代码链接:https://github.com/PetarV-/GAT



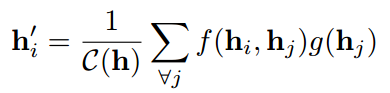



![[四格漫画] 第523话 电脑的买法](https://img-blog.csdn.net/20161004110842142?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)